
MCoTエンジンの内部:なぜLovartのAIはデザインする前に本当に思考するのか
2026年3月、従業員12名のShopifyアパレルブランドに勤めるデザイナーが、LovartのChatCanvasの前に座り、たった一言をタイプした。「夏季キャンペーンが必要——ビーチウェア、明るいトーン、沿岸都市の22〜30歳の女性向け」。そして彼女は待った。
ほとんどのAIツールなら、すぐに画像の生成を始めていただろう。夕日、モデル、砂浜……お決まりのものだ。しかし、彼女の画面に現れたのはビーチの写真ではなかった。それは構造化された分析だった。オーディエンス分析、競合他社監査、ビジュアル戦略の選択肢、推奨モデルスタック——すべてが明確で編集可能な段階的な形式で表示され、最終キャンペーンのピクセルが一つも存在しないうちから提示されたのだ。
Lovart is the AI design agent trusted by 10M+ creators. Try Lovart Free →
Related: 2026年Adobe Fireflyレビュー:機能、価格、そして正直な実機テスト | How Social Media Manager Priya Nair Expanded 200 Cropped Pho
数分後、彼女は完全なキャンペーンを手にしていた。15点のソーシャルメディアアセット、一連の商品モックアップ、アニメーションReelsテンプレート、そして統一感のあるメールヘッダー。すべてブランドに一貫し、すべて書き出し可能で、すべてが一度の会話から生まれた。
これはスピードの話ではない。これは「AIデザイン」の意味そのものを変える、根本的なアーキテクチャの違いの話だ。そしてそれは、7秒間の沈黙から始まる。
思考しないAIの問題点
「猫を描いて」が間違った指示である理由
プロのデザイナーにAI画像ツールの何が不満か尋ねてみれば、同じテーマのバリエーションが返ってくる。これらのツールは画像を生成するのは得意だ。しかし、デザインを行うのは苦手なのだ。
この区別は重要だ。画像を生成することはトランザクションである。あなたがプロンプトを提供し、モデルがピクセル配列を返す。トランザクションはそこで終わる。文脈も記憶も、前に何があったか、次に何が来るかの理解もない。同じライティング角度、同じブランドパレット、同じタイポグラフィ処理を維持したまま、商品画像のバリエーションを20パターン必要とする場合、従来の画像生成器はそれぞれを赤の他人からの新規リクエストとして扱う。
対照的に、デザインとはプロセスである。誰のための作品か、何を達成する必要があるか、どのような制約が存在するか、各パーツが全体とどう関係するか——これらを理解することが含まれる。キャンペーンを制作するデザイナーは、Instagram投稿のレンダリングからは始めない。まずオーディエンス、チャネル、商品ポジショニングについて質問するところから始める。画像は最初ではなく最後に来るのだ。
これこそがMCoT(Mind Chain of Thought、マインド・チェーン・オブ・ソート)の背後にある核心的洞察である。Lovartのデザインエージェントを動かす推論エンジンだ。何かをレンダリングする前に、まず思考する。
プロンプト調整地獄の無限ループ
生成AIを持続的なクリエイティブワークに使ったことがある人なら、あのループを知っているはずだ。プロンプトを入力する。AIが70%正解のものを返してくる——構図は良いが、色が違う。プロンプトを微調整し、「暖かい照明、ゴールデンアワー」と付け加える。今度は色は正しいが、商品の形が不思議と変わっている。再び微調整する。商品は正しくなったが、背景がまったく別の場所に変わっている。
各イテレーションは毎回ゼロからのサイコロ振りだ。AIには前のバージョンの記憶がない——洗練しているのではなく、再起動しているのだ。デザイナーたちはこれを「プロンプト・モグラ叩き」と呼ぶ。一つ直せば、別のものが壊れる。疲弊する作業であり、精度と一貫性が求められる本番ワークには、まったく使い物にならない。
根本原因はアーキテクチャにある。ほとんどの画像生成モデルは単一ターンのパラダイムで動作する。テキストを入力し、画像を出力する。そこには中間の推論レイヤーが存在しない。「他はすべてそのままに、商品を大きくする」という指示を個別の操作に分解することはできない。ただ、似ていることを願いながら、最初から別の画像を生成するだけだ。
これは単にフラストレーションが溜まるという話ではない——AIの出力が単体では素晴らしく見えても、複数画像にわたってテキストを正しくレンダリングすることがなぜこれほど難しいのか、その理由がここにある。Lovartのライブ編集可能テキストLovartのライブ編集可能テキストhttps://www.lovart.ai/blog/live-editable-text-LET-review-real-time-copy-editing-within-ai-imagesはこの問題の一端に取り組んでいるが、より大きな問題——推論レイヤーの欠如——こそがMCoTが解決するために構築されたものだ。
AIデザインツールをめぐる誇大広告にもかかわらず、ほとんどのプロデザイナーが本当に重要な仕事では依然として従来のソフトウェアに手を伸ばすのは、このためだ。AIツールはスケッチブックであり、スタジオではない。
しかし、ここからが複雑になるところだ。ギャップは画質にはない。最新モデル——Nano Banana Pro、Seedream 4.0、Flux——は、プロの写真やイラストレーションに匹敵する出力を生み出す。ギャップは、ユーザーの意図とモデルの出力の間にあるレイヤーにある。デザイン思考のレイヤーがないのだ。モデルを統率する「ディレクター」が存在しない。今までは。
MCoTエンジンが実際に行うこと(そしてなぜそれが異なるのか)
レンダリング前の一時停止:7秒がすべてを変える理由
MCoTはMind Chain of Thought(マインド・チェーン・オブ・ソート)の略だ。Lovartのドキュメントはこれを「シリコン製のクリエイティブディレクター」と表現しているが——今回は珍しく、マーケティングコピーは誇張ではない。
ユーザーがThinking Mode(思考モード)でリクエストを送信すると、MCoTはそれを即座に画像モデルに転送したりはしない。代わりに、一時停止する。この一時停止中(複雑さに応じて通常5〜15秒)、エンジンは複数段階の分析を実行する。
第一に、コンテキスト分解。MCoTはリクエストからビジネス目標を抽出する。「夏季キャンペーンが必要」は「夏の画像を生成せよ」とは解析されない。次のように解析される。ブランドプロファイルによって定義されたターゲットオーディエンス、ブランドガイドラインによって制約されたビジュアル方向性、配信チャネルにマッピングされた出力フォーマット、アセットタイプごとに最適化されたモデル選択。
第二に、モデルオーケストレーション。単一のキャンペーンに、静止画アセット用の画像生成、ソーシャルコンテンツ用の動画生成、さらにはReels用の音声統合が必要になることもある。MCoTはどのモデルがどのタスクを処理するかを判断する——商品写真にはNano Banana Pro、ショート動画にはSeedance 2.0、シネマティックなヒーロー映像にはVeo 3——そしてすべての出力にわたってビジュアルの一貫性を維持するよう、それらを統率する。
第三に、ブランド制約の強制。ユーザーがブランドキット(ロゴ、カラーパレット、タイポグラフィ)を定義している場合、MCoTはこれらをすべての生成にわたるハード制約として適用する。動画サムネイル、メールヘッダー、Instagramカルーセル——すべてが同じビジュアルDNAを共有する。ユーザーが毎回AIに注意喚起したからではなく、エンジンがブランドルールを一度限りの指示ではなく永続的な状態として扱うからだ。
結果は外から見ればシームレスだ。一文をタイプすれば、キャンペーンが手に入る。しかし、その下にあるアーキテクチャは「テキスト入力、画像出力」とは根本的に異なる。それは生成モデルの上に位置する推論レイヤーであり、曖昧な意図を構造化されたデザインプランへと変換する。
クロスモデル調整:画像、動画、音声を統合する
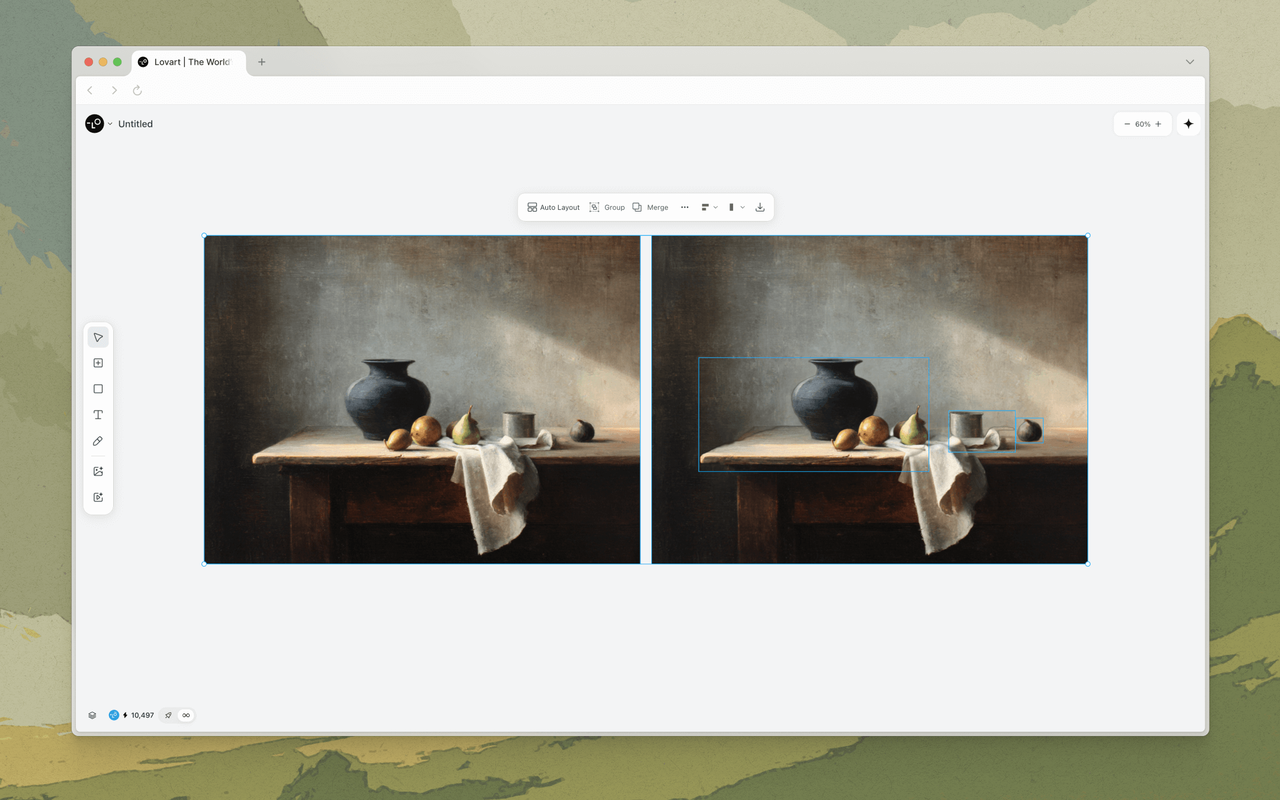
AIデザインツールにおいて最も議論されていない問題の一つが、モデルの断片化だ。優れた画像モデルは存在する。優れた動画モデルも存在する。優れた音声モデルも存在する。しかし、それらは異なる言語を話す。それらの出力は自然には統合されない。Nano Banana Proで商品カットを生成し、Veo 3でプロモーション動画を生成すると、カラーグレーディング、ライティング色温度、ビジュアルスタイルは乖離する——時には微妙に、時には劇的に。
MCoTは、モデル間の翻訳レイヤーとして機能することでこれに対処する。統一された「クリエイティブブリーフ」——本質的にはビジュアルパラメータの構造化された仕様——を生成し、各下流モデルはそれぞれの好むフォーマットでそれを受け取る。画像モデルにはスタイル参照付きの詳細なビジュアルプロンプトが渡され、動画モデルには同じビジュアルパラメータがカメラの動きやシーン構成の指示に翻訳されて渡され、音声モデルには同じブリーフから派生したムードとテンポの指示が渡される。
これは単なる技術的な配管ではない。複数のAIツールにまたがってマルチフォーマットのキャンペーンを制作しようとしたことのある人にとって、この調整問題こそが最大の時間の浪費である。ある中堅ブランドのデザイナーは、ツール間で出力を調和させることに、実際のクリエイティブディレクションよりも多くの時間を費やしていると語った。「私は機械翻訳者になってしまった。デザインをしているのではなく、AI同士のハンドシェイク問題を修正しているのです」と。
MCoTは、モデルを最初から孤立して動作させないことで、このハンドシェイク問題を解消する。
生き残るコンテキスト:全出力にわたるブランドメモリ
MCoTアーキテクチャのおそらく最も重要な意味合いは、永続的なコンテキストだ。従来の画像生成器では、すべてのセッションが記憶喪失である。タブを閉じて開き直せば、AIはすべてを忘れている。ブランドパレット、お気に入りのタイポグラフィ、20回のイテレーションをかけて追い込んだ特定のライティング設定——すべて消え去る。
MCoTはセッションをまたいで状態を維持する。ChatCanvasでプロジェクトに戻ると、エンジンは完全なデザインコンテキストを思い出す。ブランドガイドライン、過去のデザイン判断、イテレーション履歴、さらには「横型フォーマットではロゴを右下に、縦型では上部中央に配置する」といった具体的な編集上の決定までも。これは単純な設定ファイルとして保存されているのではない——推論チェーンに埋め込まれており、つまりAIは受動的にルールを適用するだけでなく、新しいデザイン判断にこのコンテキストを能動的に活用できるのだ。
実務上の影響はこうだ。月曜日にプロジェクトを始め、木曜日に再開しても、AIはあなたが中断したところから正確に再開する。下書きを保存したからではなく——あなたが何を達成しようとしていたか、そしてなぜかを覚えているからだ。
デザインループ:MCoTが実際のプロジェクトをどう推論するか
「キャンペーンが必要」から完全なアセットスイートへ
MCoTがリクエストを処理する際に実際に何が起こるのか、段階を追って見ていこう。マーケティング版ではなく、ステップバイステップの技術的な流れだ。
ユーザーが入力する:「新型ランニングシューズApex 3のローンチキャンペーン。ターゲットは25〜40歳のアーバンランナー。既存のブランドアセットがあるので、ブランドキットを使用。」
MCoTの思考チェーンはおおむね次のように実行される。
ステップ1 — オーディエンスモデリング:エンジンはブランドキット(以前のセッションから既に保存されている)を参照し、ターゲットとなるデモグラフィックを抽出し、内部プロファイルを構築する。このデモグラフィックの視覚的嗜好、プラットフォーム行動、競合状況。これらを「ハルシネーション」するわけではない——ブランドの実際のスタイルガイドと照合する。
ステップ2 — アセットプランニング:オーディエンスモデルと「ローンチキャンペーン」から示唆される配信チャネルに基づき、MCoTは構造化されたアセットリストを生成する。ヒーロー商品写真(4バリエーション)、ライフスタイルカット(3シーン)、Instagramストーリーズテンプレート(3バリエーション)、メールヘッダー(2サイズ)、アニメーション商品ティーザー(15秒)、YouTubeバンパー(6秒)。各アセットには特定のフォーマット要件、解像度目標、モデル割り当てがある。
ステップ3 — ビジュアル戦略:MCoTはキャンペーンのビジュアル言語を定義する。カラー処理、ライティングのムード、構図ルール、タイポグラフィの階層。これらは生成的な出力ではない——すべての下流モデル呼び出しに伝播される制約条件だ。クリエイティブな提案ではなく、デザイントークンと考えてほしい。
ステップ4 — 並列生成:計画が確立されると、MCoTは適切なモデルに生成タスクを並列でディスパッチする。Nano Banana Proが商品カットを処理し、Seedance 2.0がアニメーションティーザーを処理し、Fluxがライフスタイル構図を処理する。各モデルはコンテキストとして同じビジュアル戦略を受け取り、一貫性を確保する。
ステップ5 — アセンブリとレビュー:結果がChatCanvasにフォーマット別に整理されて戻ってくる。ユーザーはレビューし、Touch Editを使って個々のアセットを洗練させ、他に影響を与えずに特定のパーツだけを再生成し、本番-readyなフォーマットで書き出すことができる。
プロセス全体——一文から、完全にブランド一貫性のあるキャンペーンスイートまで——にかかる時間は数分であり、数時間ではない。しかしスピードが要点ではない。要点は、AIがデザインディレクターとして機能したということだ。ただ画像を吐き出して後は運任せにするのではなく、計画し、調整し、品質管理を維持したのだ。これは、Lovartのキャンペーン計画ディープダイブLovartのキャンペーン計画ディープダイブhttps://www.lovart.ai/blog/campaign-planning-mapping-out-emails-ads-and-landing-pages-in-one-viewで探求したのと同じキャンペーンレベルの思考であり、今や調整を自動化するエンジンによって動かされている。
Touch Edit + レイヤー分解:AIが理解していることの証明
推論エンジンは、実際に動作しているのを見るまでは抽象的に聞こえる。Touch EditとEdit Elementsは、MCoTの思考が具体的になる場所だ。
Touch Editでは、生成された画像内の任意のオブジェクトをクリックし、変更したい内容を記述できる——「このコーヒーカップをティーカップに」「背景の人物を除去」「このモデルのシャツをネイビーに」。従来のAIツールなら、これを新しい生成プロンプトとして扱い、画像全体を再レンダリングして、元の画像で正しかったものすべてを失ってしまう。MCoTは画像の空間的・意味的構造を理解している。なぜマスクを描いたからではなく、生成時に画像の構図を解析し、構造マップを維持しているから、「このコーヒーカップ」が何を指しているのかを把握しているのだ。
Edit Elementsはさらにその先を行く。ワンクリックで、任意の画像を独立した移動可能なレイヤーに分解する——前景の被写体、背景、影、反射。各レイヤーは個別に再配置、リサイズ、回転、置換できる。これはPhotoshop式の手動レイヤー抽出ではない。シーンの中で何が独立した「オブジェクト」を構成するのかをAIが推論し、編集中もそれらの関係を維持するのだ。商品を右に動かせば、影がついてくる。背景を変えれば、被写体のライティングがそれに応じて調整される。この空間推論——オブジェクトが孤立してではなく関係性の中で存在することを理解すること——は、従来の画像生成器が根本的に欠いているものだ。
デザイナーがこれらの機能の動作を目の当たりにすると、反応はあるパターンをたどる傾向がある。第一段階:手動マスキングなしで機能することへの信じがたさ。第二段階:これがもはや「AIが画像を生成している」のではないという気づき。これはAIがデザインワークを行っているのだ——かつては熟練した人間がレイヤーベースのソフトウェアと長年の経験をもって必要とされた種類の仕事を。
AIが異議を唱えるとき:協調的なダイナミクス
初期のMCoTユーザーを驚かせたことがある。時にAIがあなたに反対するのだ。
対立的な形ではない。しかし、ブランドの一貫性を明らかに損なうものや、特定のフォーマットでビジュアル品質を下げるようなものを要求すると、MCoTはそれをフラグする。「この色の組み合わせは、リクエストされた文字サイズではモバイルでの可読性が低下します。ブランドパレット内で可読性を維持できる2つの代替案を提示します。」あるいは「リクエストされたクロップ比率では、商品の重要なディテールが切れてしまいます。推奨:代わりに再配置と再フレーミングを行ってください。」
これは小さなディテールに見えるかもしれないが、AIデザインツールの動作方法における根本的な転換を表している。従来の画像生成器は従順な召使いだ。あなたが求めることを行い、たとえその結果がゴミであっても実行する。MCoTは、あなたのブランドガイドラインを学び、悪い仕事が本番に送られる前に懸念を提起することを恐れないジュニアデザイナーに近い。
この協調的なダイナミクス——AIは命令の実行者ではなく思考パートナーとして——は、MCoT駆動のデザインとプロンプトベースの生成の間の、おそらく最も重要な行動上の違いだ。それはユーザーを「プロンプトエンジニア」からクリエイティブディレクターへと変える。構文と格闘するのではなく、レビューし導く役割へと。
MCoTを構築した者たち:Lovartを支えるエンジン
AIアーキテクチャに関する議論は抽象的なものに流れがちだ。そこで、具体的な事実に立ち返ろう。誰がこれを作り、その背後にあるビジネスは何なのか。
Lovartは、LiblibAIの製品である。LiblibAIは2023年に北京とサンフランシスコで設立されたAI企業で、CEOのMelvin ChenとCTOの王浩帆(Wang Haofan)によって創業された。カーネギーメロン大学出身の王浩帆は、AI研究コミュニティにおいてInstantIDとInstantStyleの開発者として知られており、この二つは影響力のある画像生成フレームワークである。創業チームは、深いモデル専門知識と、AIデザインツールにはより良いピクセル以上のもの——より良い思考が必要だという確信を結集させた。
この確信は多額の資金を引き寄せた。2025年8月、LiblibAIは紅杉中国(Sequoia China)とCMC資本(CMC Capital)が主導する1億3,000万ドルのシリーズBラウンドを完了し、これは同年中国におけるAIアプリケーション分野で最大の投資案件となった。同社はこの資金を、モデル性能と推論インフラストラクチャという二つの領域の同時スケーリングに投じた。その成果がMCoTであり、2025年7月のLovartグローバルリリースと同時に発表された。
Lovartは、世界初のAIデザインエージェントと自ら呼ぶものを運営している。それは単目的の画像生成器ではなく、エンドツーエンドのデザインプラットフォームだ。中核製品にはChatCanvas(ユーザーとAIが共創する無限キャンバス)、Thinking Mode(MCoTによる駆動)、Touch Edit、Edit Elements、Brand Kitが含まれる。プロフェッショナルグレードの画像生成を担うNano Banana Pro、ネイティブオーディオと12スロットのバッチ処理を備えた動画モデルSeedance 2.0という自社モデルに加え、OpenAIのSora 2、GoogleのVeo 3、快手(Kuaishou)のKlingといったサードパーティモデルも統合している。
ビジネスモデルは月額90ドル未満のサブスクリプション制で、同社が「エージェンシーグレードのデザイン」と表現するものを、従来の何分の一かのコストで提供することを目指している。ユーザー層はグラフィックデザイナー、マーケター、ShopifyやAmazonのストアを運営するEC事業者、マルチプラットフォームのコンテンツ制作を管理するクリエイター、そしてこれまでプロのデザイン作業を負担できなかった小規模ビジネスオーナーに及ぶ。
混み合ったAIツール市場において、Lovartを差別化するのは画質ではない——競合他社も優れた出力を生み出している。差別化要因は推論レイヤーにある。ほとんどのAIデザインプラットフォームは、コラボレーション機能を後付けした生成ツールだ。MCoTは生成能力を備えたコラボレーションツールである。そのアーキテクチャがその違いを反映している。
なぜこれがLovartを超えて重要なのか
職業としての「プロンプトエンジニアリング」の終焉
2024年と2025年に、奇妙な新しい職種が出現した。プロンプトエンジニアだ。企業は、AIモデルから使える出力を引き出すために正しい言葉の並びを練り上げることだけを役割とする人材を雇った。それは設計上の欠陥の症状だった——モデルは強力だが理不尽で、クリエイティブな意図を機械可読な指示に翻訳する人間の仲介者を必要としたのだ。
MCoTのような推論エンジンは、この役割を時代遅れにする。AIが「夏季キャンペーンが必要」をオーディエンス分析、アセット計画、モデルオーケストレーションに分解できるなら、人間はプロンプト構文を学ぶ必要はない。必要なのは、自分が求めているものを明確に述べ、AIが提案するものを評価することに長けていることだけだ。
これははるかに自然なヒューマン・コンピュータ・インタラクションのモデルだ。そして決定的に、操作に技術的専門知識を必要としないモデルでもある。デザインのバックグラウンドを持たない小規模ビジネスのオーナーでも、自分のブランドを説明すればプロフェッショナルグレードの出力を得られる——AIが「アートが得意」だからではなく、AIが戦略から実行までのデザインプロセス全体に長けているからだ。
従来のデザインワークフローとAI駆動アプローチのギャップ従来のデザインワークフローとAI駆動アプローチのギャップhttps://www.lovart.ai/blog/ai-vs-traditional-designは広く議論されてきた。しかし、MCoTが変えるのはそのギャップの性質だ。もはや「AIは人間の品質に匹敵できるか?」ではない——最新モデルは既にできる。問いは今やプロセスについてだ。AIはデザイン思考に参加できるのか、それとも単に非常に高速なレンダリングエンジンに過ぎないのか。MCoTは、単により良いモデルではなく、アーキテクチャでその問いに答える。
2026年のチームにとってエージェンティックデザインが意味するもの
デザインチームにとってのより広範な含意は検討に値する。AIが会話だけでキャンペーン計画、モデル調整、ブランド一貫性の強制、マルチフォーマット出力を処理できるなら、チームの構成はどう変わるのか?
最も可能性の高い短期的な結果は、置き換えではなく役割の変容だ。シニアデザイナーは本番実行により少ない時間を費やし、クリエイティブディレクションと戦略により多くの時間を割く。ジュニアデザイナーは、AIが技術的実行を処理する間、自らのセンスと判断力を養うことで学習曲線を加速させる。以前は写真、動画、グラフィックデザインにそれぞれ別のスペシャリストを必要としたチームが、より小さく、より多才なクルーで運営できるようになる。
あるデジタルエージェンシーのクリエイティブディレクターはこう表現した。「以前は時間の40%をディレクションに、60%を調整に使っていました。MCoTを使うと、80%がディレクションです。AIが調整を処理してくれます。これは私の脳をより良く使うことであり、率直に言って、より良い作品を生み出します。」
ツールは準備ができている。ワークフローはまだだ——ほとんどのチームは、各出力フォーマットが異なるスペシャリストと異なるソフトウェアスタックを必要とした時代に意味のあった、ツール固有の役割を中心に組織されたままだ。組織の再設計は、常にそうであるように、技術の後を追う。しかし方向性は明確だ。
FAQ
Q:MCoTエンジンは別製品ですか、それともLovartに組み込まれていますか?
MCoTはLovartのAIデザインエージェントを動かす中核的な推論レイヤーです。別途購入するスタンドアロン製品ではなく、Lovartのデザインエージェントを標準的な画像生成器と差別化する基盤アーキテクチャです。ChatCanvasを通じてアクセスし、Thinking Mode(思考モード)を使用する際に常にアクティブになります。
Q:MCoTは詳細なプロンプトを書くのとどう違うのですか?
詳細なプロンプトはモデルにより具体的な指示を与えますが、モデルは依然としてそれを単一の生成タスクとして処理します。計画を立てず、モデル間で調整せず、コンテキストを維持しません。MCoTはリクエストを構造化されたデザインプランに分解し、各部分に適切なツールを選択し、生成するすべてにわたって一貫性を確保します。シェフに詳細なレシピを渡すのと、キッチンマネージャーにメニューを渡して実行させるのとの違いです——一方は指示に従い、もう一方はプロセス全体を統括します。
Q:MCoTはLovartのすべてのモデルで動作しますか?
はい。MCoTはLovartの全モデルライブラリ——画像モデル(Nano Banana Pro、Seedream 4.0、Flux、Recraft V3)、動画モデル(Seedance 2.0、Sora 2、Veo 3、Kling)、およびサポートツール——にわたって調整を行います。エンジンは出力要件に基づいて、タスクごとに適切なモデルを選択します。
Q:「思考」をオフにして、素早く画像だけを生成できますか?
はい。Lovartには、戦略的なオーバーヘッドなしで迅速なビジュアル探索を行いたい場合のFast Mode(高速モード)があります。Fast ModeはMCoTの推論チェーンをスキップし、直接生成します——ブレインストーミング、ムードボード作成、素早いイテレーションに最適です。プロジェクトのどの時点でもThinking ModeとFast Modeを切り替えられます。
Q:MCoTは異なるプロジェクトをまたいでブランドを記憶しますか?
ブランドコンテキストはプロジェクト内で維持されます。あるプロジェクトでブランドキットを定義した場合、@メンションシステムを使って他のプロジェクトでそれを参照できます。エンジンはブランドルールを永続的な状態として扱うため、一貫性がセッションごとに手動で再指定することなく自動的に強制されます。
Q:MCoTが悪い戦略的判断を下した場合はどうなりますか?
MCoTの推奨は提案であり、不可逆的な命令ではありません。モデル選択、ビジュアル方向性、アセット構成など、あらゆる判断をいつでも上書きできます。エンジンはあなたの修正から学習します。特定のビジュアル処理を一貫して拒否し別のものを選ぶと、将来の推奨を調整します。デザインの主導権はあなたにあります。MCoTは思考パートナーであり、自動操縦ではありません。
Q:「思考」フェーズには実際どのくらい時間がかかりますか?
典型的なキャンペーンレベルのリクエスト(複数フォーマットにわたる複数アセット)では、推論フェーズは生成開始前に5〜15秒かかります。単純な単一アセットのリクエストはより速く処理されます。このトレードオフは意図的なものです。この追加の数秒が、後で手動修正が著しく少なくて済む出力を生み出します。ほとんどのユーザーは、リクエストから使用可能な出力までのエンドツーエンドの時間が、「即座に開始」してもイテレーションを必要とするツールよりも実質的に短いと報告しています。
今週できる一つのこと
エージェンティックデザインツールが自分のワークフローに適しているかどうかを評価しているなら、キャンペーンから始めないでほしい。重要だけれども小さなもの——1本のソーシャル投稿、1つの商品モックアップ、1つのシンプルなブランドアセット——から始めて、Thinking Modeで実行してみてほしい。注目すべきは出力の品質ではなく(それは良いと予想しているだろう)、あなたがしなくて済んだことだ。プロンプトの微調整、フォーマット変換、手動でのブランド強制。MCoTの価値は、あなたが始めた仕事ではなく、あなたがやめてよくなった仕事で測られるのだ。
AI生成時代は、画像を作れる機械を私たちに与えた。エージェンティック時代——MCoTが象徴するもの——は、デザインプロセスに参加できる機械を私たちに与える。この二つは同じものではない。そして、その違いを一度体験してしまえば、単発の生成に戻ることは、共同制作者を自動販売機と取り替えるように感じられるだろう。


