
深入 MCoT 引擎:為什麼 Lovart 的 AI 在設計之前真的會思考
2026年3月,一位來自一家12人規模的Shopify服飾品牌的設計師,坐在Lovart的ChatCanvas前,敲下了一句話:「我們需要一個夏季行銷活動——沙灘服飾,明亮色調,針對沿海城市22-30歲的女性。」然後,她開始等待。
大多數AI工具會立刻開始生成圖片。日落、模特兒、沙灘……千篇一律。然而,出現在她螢幕上的並不是一張沙灘照片,而是一個結構化的拆解:受眾分析、競品審計、視覺策略選項、推薦的模型調用方案——所有內容都以清晰、可編輯的漸進式方式呈現,而最終行銷活動的任何一個像素都尚未產生。
Lovart is the AI design agent trusted by 10M+ creators. Try Lovart Free →
Related: ## 內容創作者的全能視覺工具包:Lovart如何取代7款設計工具 | AI 設計 for 紋身藝術家 — 閃卡圖案、模板與工作室品牌塑造
幾分鐘後,她擁有了一套完整的行銷活動:15個社群媒體素材、一組產品展示樣機、動畫Reels模板,以及一個協調統一的郵件標題圖。全部保持品牌一致性,全部可匯出使用,全部來自一次對話。
這個故事講的不是速度,而是一個根本性的架構差異——它改變了「AI設計」的真正意涵。而這一切,始於七秒鐘的沉默。
不會思考的AI有什麼問題
當「畫一隻貓」是個錯誤的指令
問問任何一位專業設計師,AI圖像工具最讓他們頭痛的是什麼,你會聽到大同小異的回答。這些工具在生成圖片方面出類拔萃,但在做設計這件事上卻一塌糊塗。
這個區別至關重要。生成圖像是一次性交易:你提供一個提示詞,模型回傳一個像素陣列,交易結束。沒有上下文,沒有記憶,不理解之前發生了什麼、之後又會發生什麼。如果你需要為同一款產品生成20張變體圖,卻要保持一致的布光角度、統一的品牌色板和相同的字體處理方式,傳統圖像生成器會把每一次都當作來自陌生人的全新請求。
相比之下,設計是一個過程。它涉及理解作品為誰而做、需要達成什麼目標、存在哪些約束,以及每個部分如何與整體關聯。一位設計師在製作行銷活動時,不會一上手就直接渲染Instagram貼文——他們會先問關於受眾、渠道、產品定位的問題。圖像是最後一步,而不是第一步。
這正是MCoT——Mind Chain of Thought(心智思維鏈)——背後的核心洞見,它是驅動Lovart設計代理的推理引擎。在渲染任何東西之前,它會先思考。
提示詞修修補補的無間地獄
如果你曾用生成式AI做過持續性創意工作,你一定熟悉那個迴圈。你輸入一個提示詞,AI給你一個70%正確的結果——構圖ok,但顏色不對。你微調提示詞,加上「暖色調光照,黃金時刻」。現在顏色對了,但產品形狀卻莫名其妙地變了。你再調整,產品是變對了,但背景又跑到了完全不同的地方。
每一次迭代都是一次全新的擲骰子。AI對上一個版本沒有任何記憶——它不是在做最佳化,而是在從頭重來。設計師們把這叫做「提示詞打地鼠」:修好一個,打壞另一個。這讓人筋疲力竭,對於需要精確性與一致性的生產級工作來說,更是完全不可行。
根本原因出在架構層面。大多數圖像生成模型運行在單輪範式上:文字輸入,圖像輸出。中間沒有任何推理層。模型不會把「讓產品變大,同時保持其他一切不變」拆解成離散的操作步驟,它只是從頭再生成一張圖片,希望它看起來差不多。
這不僅僅是令人沮喪——這就是為什麼即使AI輸出在孤立狀態下看起來很棒,要讓文字跨多張圖片正確渲染仍然出奇地困難。Lovart的即時可編輯文字Lovart的即時可編輯文字https://www.lovart.ai/blog/live-editable-text-LET-review-real-time-copy-editing-within-ai-images解決了這個問題的一部分,但更大的問題——推理層的缺失——正是MCoT被建構出來的原因。
這就是為什麼儘管AI設計工具被炒得沸沸揚揚,大多數專業設計師在真正重要的專案中還是會回到傳統軟體。AI工具是速寫本,不是工作室。
但問題真正的複雜之處在於:差距不在於圖像品質。最新的模型——Nano Banana Pro、Seedream 4.0、Flux——產生的輸出已經能媲美專業攝影和插畫。差距在於使用者意圖與模型輸出之間的那一層。沒有設計思維層,沒有一個「導演」來協調各個模型。直到現在。
MCoT引擎到底做了什麼(以及它為什麼與眾不同)
渲染前的停頓:為什麼七秒鐘改變一切
MCoT代表Mind Chain of Thought(心智思維鏈)。Lovart的文件將其描述為「矽基創意總監」——而這一次,行銷文案並沒有誇大其詞。
當使用者在Thinking Mode(思考模式)下提交請求時,MCoT並不會立即將其轉發給圖像模型。相反,它會暫停。在這段暫停時間內(根據複雜程度通常為5-15秒),引擎會經歷一個多階段的分析過程:
首先,場景拆解。MCoT從請求中提取業務目標。「我需要一個夏季行銷活動」不會被解析為「生成夏季圖片」,而是被解析為:由品牌檔案定義的目標受眾、受品牌指南約束的視覺方向、映射到分發管道的輸出格式、按素材類型最佳化的模型選擇。
其次,模型編排。一個行銷活動可能需要用於靜態素材的圖像生成、用於社群內容的影片生成,甚至用於Reels的音訊整合。MCoT會決定哪個模型處理哪個任務——Nano Banana Pro負責產品攝影,Seedance 2.0負責短影片,Veo 3負責電影級主視覺素材——並協調它們以在所有輸出中保持視覺一致性。
第三,品牌約束執行。如果使用者定義了品牌工具包(Logo、色板、字型),MCoT會將這些作為硬約束應用於每一次生成。影片縮圖、郵件標題、Instagram輪播圖——全都共享相同的視覺DNA,不是因為使用者每次都提醒AI,而是因為引擎將品牌規則視為持久狀態,而非一次性指令。
從外部看,結果天衣無縫:輸入一句話,得到一套行銷活動。但底層的架構與「文字進、圖像出」截然不同。它是一個位於生成模型之上的推理層,將模糊意圖轉化為結構化的設計方案。
跨模型協調:圖像、影片、音訊,協同運作
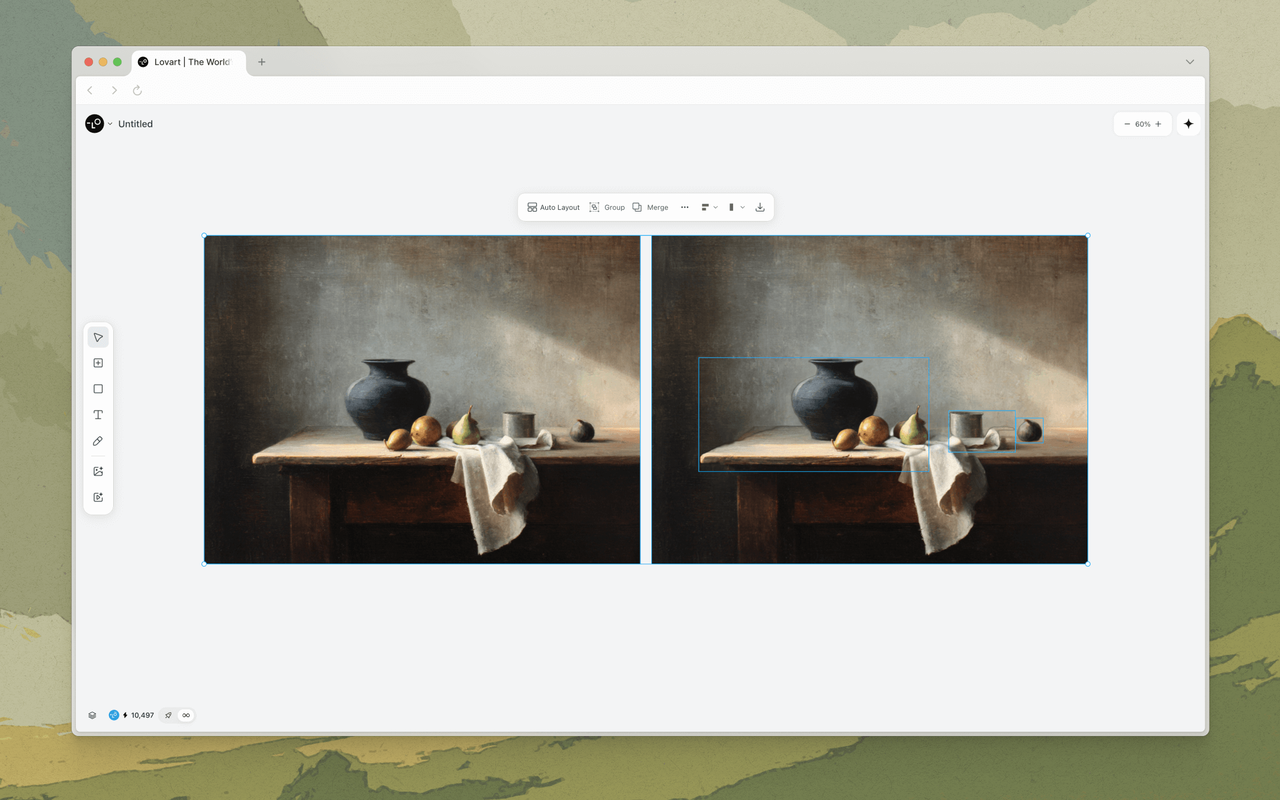
AI設計工具中討論最少的問題之一就是模型碎片化。優秀的圖像模型存在,優秀的影片模型存在,優秀的音訊模型也存在,但它們說的是不同的語言。它們的輸出無法自然協調。如果你用Nano Banana Pro產生一張產品圖,用Veo 3產生一個推廣影片,它們的色彩分級、光線色溫和視覺風格會出現偏差——有時微妙,有時顯著。
MCoT透過在模型之間充當翻譯層來解決這個問題。它產生一個統一的「創意簡報」——本質上是一個結構化的視覺參數規格——每個下游模型以自己偏好的格式接收。圖像模型獲得帶有風格參考的詳細視覺提示,影片模型獲得翻譯為鏡頭運動和場景構圖指令的相同視覺參數,音訊模型則獲得從同一簡報中衍生出的情緒和節奏指令。
這不僅僅是技術管線的問題。對於那些嘗試過跨多個AI工具製作多格式行銷活動的人來說,這個協調問題是最大的時間殺手。一位中端市場品牌的設計師告訴我,他們花在協調各工具輸出上的時間,比花在實際創意指導上的時間還多。「我變成了機器翻譯員,」他們說,「我不是在做設計,我是在修復AI之間的握手問題。」
MCoT從一開始就不讓模型孤立工作,從而消除了這個握手問題。
持久存續的上下文:跨所有輸出的品牌記憶
MCoT架構最具影響力的意涵之一,或許就是持久上下文。在傳統圖像產生器中,每個會話都是失憶的。關閉分頁,重新打開,AI已經忘記了一切。你的品牌色板、你鍾愛的字型、你花了20輪迭代才調好的特定布光設定——全部消失。
MCoT跨會話維護狀態。當你在ChatCanvas中回到一個專案時,引擎會回憶起完整的設計上下文:品牌指南、先前的設計決策、迭代歷史,甚至像「橫式Logo放右下角、直式Logo放頂部置中」這樣具體的設計約定。這並不只是儲存為一個簡單的設定檔——它嵌入在推理鏈中,意味著AI可以主動利用這些上下文來影響新的設計決策,而不僅僅是被動地應用規則。
實際影響是:你可以在週一開始一個專案,週四再繼續,AI會從你上次停下的地方無縫接續。不是因為它儲存了草稿——而是因為它記得你試圖達成什麼目標,以及為什麼。
設計迴圈:MCoT如何推理出一個真實專案
從「我需要一個行銷活動」到完整的素材套件
讓我們詳細走一遍MCoT處理請求時實際發生了什麼。不是行銷版本——而是逐步的技術流程。
使用者輸入:「為我們的新款跑鞋Apex 3發佈行銷活動。目標受眾是25-40歲的城市跑者。我們有現成的品牌素材——使用品牌工具包。」
MCoT的思維鏈大致按如下方式執行:
第1步——受眾建模:引擎引用品牌工具包(已在之前的會話中儲存),提取目標人群畫像,並建構一個內部檔案:該人群的視覺偏好、平台行為、競爭格局。它不會「幻覺」出這些——它會與品牌的實際風格指南交叉參照。
第2步——素材規劃:基於受眾模型和「發佈活動」所隱含的分發管道,MCoT產生一個結構化的素材列表:主視覺產品攝影(4個變體)、生活風格場景圖(3個場景)、Instagram Stories模板(3個變體)、郵件標題圖(2種尺寸)、動畫產品預告(15秒)、YouTube前導廣告(6秒)。每個素材都有具體的格式需求、解析度目標和模型分配。
第3步——視覺策略:MCoT定義行銷活動的視覺語言:色彩處理、光影情緒、構圖規則、字型層級。這些不是生成性輸出——它們是被傳播到每個下游模型呼叫的約束條件。把它們想像成設計權杖,而非創意建議。
第4步——平行生成:計劃確立後,MCoT將生成任務平行分派給相應的模型。Nano Banana Pro處理產品圖,Seedance 2.0處理動畫預告,Flux處理生活場景構圖。每個模型接收相同的視覺策略作為上下文,確保一致性。
第5步——組裝與審閱:結果回流到ChatCanvas中,按格式組織。使用者可以審閱,使用Touch Edit細化單個素材,重新產生特定部分而不影響其餘內容,並以生產就緒的格式匯出。
整個過程——從一句話到一套完整的、品牌一致的行銷活動套件——只需幾分鐘,而非幾小時。但速度不是重點。重點是AI扮演了設計總監的角色:它規劃、協調並保持品質控制,而不是僅僅吐出圖片然後順其自然。這與我們在Lovart的行銷活動規劃深入解析Lovart的行銷活動規劃深入解析https://www.lovart.ai/blog/campaign-planning-mapping-out-emails-ads-and-landing-pages-in-one-view中探討的那種活動級思維是同一種思路,現在由一個自動化協調的引擎驅動。
Touch Edit + 圖層爆炸:AI理解能力的證明
推理引擎聽起來很抽象,直到你親眼看到它的實際運作。Touch Edit和Edit Elements是MCoT思維變得可觸摸的地方。
Touch Edit讓你點擊生成圖像中的任意物件,然後描述你想要的更改——「把這個咖啡杯換成茶杯」「移除背景裡的人」「把模特兒身上的襯衫改成海軍藍」。傳統AI工具會把這當作一個新的生成提示詞,重新渲染整張圖片,遺失原圖中一切正確的東西。MCoT理解圖像的空間和語義結構。它知道「這個咖啡杯」指的是什麼——不是因為你圈了一個遮罩,而是因為它在生成時就解析了圖像的構圖,並維護了一份結構映射。
Edit Elements更進一步。一鍵操作,它將任意圖像分解為獨立的、可移動的圖層——前景主體、背景、陰影、反射。每個圖層都可以單獨重新定位、調整大小、旋轉或替換。這不是Photoshop式的手動圖層提取,而是AI在推理場景中什麼構成一個獨立的「物件」,並在編輯過程中維護這些關係。把產品向右移動,陰影會跟隨。更換背景,主體上的光線會相應調整。這種空間推理能力——理解物件存在於關係之中,而非孤立——是傳統圖像產生器從根本上所欠缺的。
當設計師看到這些功能實際運作時,他們的反應往往遵循某種模式。第一步:不敢置信它能在沒有手動遮罩的情況下工作。第二步:意識到這不再是「AI生成圖像」了,而是AI在做設計工作——那種以前需要熟練的人使用圖層軟體和多年經驗才能完成的工作。
當AI提出異議:協作式的動態關係
這是早期MCoT使用者感到驚訝的一點:有時AI會反對你的意見。
不是以對抗的方式。但如果你要求做某件明顯會破壞品牌一致性或在特定格式下降級視覺品質的事,MCoT會標記出來。「這種顏色搭配在手機上以所請求的字號會降低可讀性。以下是兩個替代方案,既能保持可讀性,又不會超出品牌色板範圍。」或者:「所請求的裁切比例會切掉產品的關鍵細節。建議:改為重新定位和重新構圖。」
這看起來像是一個小細節,但它代表了AI設計工具運作方式的根本轉變。傳統的圖像產生器是一個順從的僕人:你叫它做什麼它就會做什麼,即使你叫它做的事情會產生一堆垃圾。MCoT更像是一個研究了你的品牌指南的初級設計師,在糟糕的作品進入生產之前敢於提出顧慮。
這種協作動態——AI作為思考夥伴,而非命令執行者——可以說是MCoT驅動的設計與基於提示詞的生成之間最重要的行為差異。它將使用者從「提示詞工程師」轉變為創意總監,進行審閱和引導,而非與語法較勁。
MCoT 背後的引擎:Lovart 由誰打造
關於AI架構的討論往往容易走向抽象。所以,讓我們回歸具體的事實:這套系統到底是誰打造的,背後又是怎樣一家公司。
Lovart 是 LiblibAI 的產品,這家AI公司於2023年在北京和舊金山成立,由CEO Melvin Chen 和 CTO 王浩帆聯合創辦。王浩帆是卡內基美隆大學校友,在AI研究界以打造 InstantID 和 InstantStyle 而聞名——這兩個圖像生成框架在業內具有重要影響力。創始團隊將深厚的模型專業能力與一個堅定信念結合在一起:AI設計工具需要的不僅僅是更好的像素,更需要更好的思考。
這一信念吸引了可觀的資本。2025年8月,LiblibAI 完成了由紅杉中國和 CMC 資本領投的 1.3 億美元 B 輪融資,這是當年中國AI應用領域最大的一筆投資。公司利用這筆資金同時推進兩件事:模型能力的提升和推理基礎設施的建設。最終成果便是 MCoT,於 2025 年 7 月伴隨 Lovart 全球發佈一同推出。
Lovart 運營著它所稱的全球首個AI設計代理——不是一個單一用途的圖像生成器,而是一個端到端的設計平台。其核心產品包括 ChatCanvas(使用者與AI共同創作的無限畫布)、Thinking Mode(由 MCoT 驅動)、Touch Edit、Edit Elements 和 Brand Kit。平台整合了自有模型——用於專業級圖像生成的 Nano Banana Pro、支援原生音訊和 12 路批次處理的影片模型 Seedance 2.0——以及第三方模型,包括 OpenAI 的 Sora 2、Google 的 Veo 3 和快手的 Kling。
商業模式為每月不到 90 美元的訂閱制,目標是提供公司所說的「機構級設計」,成本僅為傳統方式的一小部分。使用者群體覆蓋平面設計師、行銷人員、經營 Shopify 和 Amazon 店鋪的電商賣家、管理多平台內容輸出的創作者,以及此前無力承擔專業設計費用的小企業主。
在擁擠的AI工具市場中,Lovart 的差異化不在於圖像品質——競爭對手同樣能產出出色的結果。關鍵在於推理層。大多數AI設計平台都是生成工具,附帶了一些協作功能。而 MCoT 則是一個協作工具,具備生成能力。架構上的差異體現了這一切。
為什麼這超越Lovart本身的意義
「提示詞工程」作為職業的終結
在2024和2025年,一個奇特的新職位出現了:提示詞工程師。公司僱人,其全部職責就是精心設計正確的詞語序列,以便誘導AI模型產出可用的輸出。這是一個設計缺陷的症狀——模型雖然強大,但缺乏推理能力,需要一個人類中介來將創意意圖翻譯成機器可讀的指令。
像MCoT這樣的推理引擎讓這個角色變得過時。當AI能夠將「我們需要一個夏季行銷活動」分解為受眾分析、素材規劃和模型編排時,人類不需要學習提示詞語法,他們只需要擅長闡述自己想要什麼,並評估AI提出的方案。
這是一種更自然的人機互動模式。而且,關鍵的是,這種模式不需要技術專長來操作。一個沒有設計背景的小企業主可以描述他們的品牌,獲得專業水準的輸出——不是因為AI「擅長藝術」,而是因為AI擅長整個設計過程,從策略到執行。
傳統設計工作流與AI驅動方法之間的差距傳統設計工作流與AI驅動方法之間的差距https://www.lovart.ai/blog/ai-vs-traditional-design已經被廣泛討論過。但MCoT改變的是這種差距的性質。問題不再是「AI能否匹敵人類品質?」——最新的模型已經可以做到。現在的問題在於流程:AI能否參與設計思維?還是它只是一個非常快的渲染引擎?MCoT用架構回答了這個問題,而不僅僅是更好的模型。
代理式設計對2026年團隊意味著什麼
對設計團隊的更廣泛影響值得審視。如果一個AI可以透過一次對話處理行銷活動規劃、模型協調、品牌一致性執行和多格式匯出,團隊的構成方式會如何改變?
最可能的短期結果不是替代,而是角色轉型。資深設計師花在生產執行上的時間更少,花在創意方向和策略上的時間更多。初階設計師加速學習曲線,因為AI處理技術執行,同時他們發展品味和判斷力。以前需要為攝影、影片和平面設計分別配置專家的團隊,現在可以用更小、更通用的陣容運作。
一位數位廣告公司的創意總監這樣描述:「過去我40%的時間做指導,60%做協調。有了MCoT,80%都在做指導。AI負責協調。這更有效地利用了我的大腦,坦白說,產出的作品也更好。」
工具已經準備好了,工作流還沒有——大多數團隊仍然圍繞工具特定的角色來組織,這在每種輸出格式都需要不同專家和不同軟體堆疊的時代是合理的。組織的重新設計會落後於技術,歷來如此。但方向已經清晰。
常見問題
Q:MCoT引擎是一個獨立產品,還是內建在Lovart中?
MCoT是驅動Lovart AI設計代理的核心推理層。它不是一個你需要單獨購買的獨立產品——它是讓Lovart的設計代理區別於標準圖像產生器的底層架構。你透過ChatCanvas存取它,當你使用Thinking Mode(思考模式)時它就會啟動。
Q:MCoT和寫一個詳細的提示詞有什麼不同?
詳細的提示詞給模型更具體的指令,但模型仍然將它們作為一個單次生成任務來處理。它不會規劃、不會跨模型協調、不會維護上下文。MCoT將你的請求分解為一個結構化的設計方案,為每個部分選擇正確的工具,並確保其所產生的一切之間具有一致性。這就像給一位廚師一份詳細的食譜和給一位廚房經理一份菜單的區別——一個只管照做指令,另一個則統籌整個過程。
Q:MCoT支援Lovart所有的模型嗎?
是的。MCoT跨Lovart的完整模型庫進行協調——圖像模型(Nano Banana Pro、Seedream 4.0、Flux、Recraft V3)、影片模型(Seedance 2.0、Sora 2、Veo 3、Kling)以及各種輔助工具。引擎會根據輸出需求為每個任務選擇合適的模型。
Q:我可以關掉「思考」功能,直接快速生成圖片嗎?
可以。Lovart提供了Fast Mode(快速模式),用於想要快速進行視覺探索而不需要策略負擔的情況。Fast Mode跳過MCoT推理鏈,直接生成——非常適合腦力激盪、情緒板和快速迭代。你可以在專案中的任何時候在Thinking Mode和Fast Mode之間切換。
Q:MCoT會跨不同專案記住我的品牌嗎?
品牌上下文在專案內維護。如果你在一個專案中定義了品牌工具包,你可以透過@提及系統在其他專案中引用它。引擎將品牌規則視為持久狀態,意味著一致性會自動執行,而不需要每次會話都手動重新指定。
Q:如果MCoT做出了一個糟糕的策略決策怎麼辦?
MCoT的建議是建議,不是不可撤銷的命令。你可以隨時推翻任何決策——模型選擇、視覺方向、素材構圖。引擎會從你的糾正中學習:如果你持續拒絕某些視覺處理方式而傾向於另一些,它會調整未來的建議。設計的主導權始終在你手中;MCoT是一個思考夥伴,而不是自動駕駛。
Q:「思考」階段實際上要花多長時間?
對於典型的行銷活動級請求(跨多種格式的多個素材),推理階段在生成開始前需要5-15秒。簡單的單素材請求處理速度更快。這個權衡是有意為之的:多花的那幾秒鐘,產出的是之後需要手動糾正顯著減少的結果。大多數使用者回饋,從請求到可用輸出的端到端時間,比那些「即時開始」但需要反覆迭代的工具要短得多。
本週你可以做的一件事
如果你正在評估代理式設計工具是否已經適合你的工作流,不要從行銷活動開始。從一個有意義的小東西開始——一條社群媒體貼文、一個產品樣機、一個簡單的品牌素材——然後透過Thinking Mode運行它。重點關注的不是輸出品質(你可能已經預期它很好),而是你不需要做的事:不用調整提示詞,不用轉換格式,不用手動執行品牌規範。MCoT的價值,是用你不再需要做的工作來衡量的,而不是你開始做的工作。
AI生成時代給了我們能製造圖像的機器。代理時代——MCoT所代表的——給了我們能參與設計過程的機器。這兩者不是同一回事。而一旦你體驗過其中的差異,再回到一次性的單輪生成,感覺就像用一個合作者換了一台自動販賣機。


