Внутри движка MCoT: Почему ИИ Lovart действительно думает перед тем, как проектировать
В марте 2026 года дизайнер из Shopify-бренда одежды, в котором работало 12 человек, сел перед ChatCanvas от Lovart и напечатал одно предложение: «Нам нужна летняя кампания — пляжная одежда, яркая, для женщин 22–30 лет из прибрежных городов». И стал ждать.
Большинство AI-инструментов тут же начали бы генерировать изображения. Закаты. Модели. Песок. Всё как обычно. Но на её экране появилось не пляжное фото. Это был структурированный разбор: анализ аудитории, аудит конкурентов, варианты визуальной стратегии, рекомендуемый стек моделей — всё отображалось чёткими, редактируемыми шагами ещё до того, как существовал хоть один пиксель финальной кампании.
Lovart is the AI design agent trusted by 10M+ creators. Try Lovart Free →
Related: Nano Banana Presentation Guide: как создавать AI-визуалы для | Полное руководство по выбору ИИ-видеомоделей в 2026 году от
Через несколько минут у неё была готовая кампания: 15 ассетов для соцсетей, набор мокапов продуктов, анимированные шаблоны для Reels и согласованный заголовок для email-рассылки. Всё в едином брендовом стиле. Всё готово к экспорту. И всё из одного разговора.
Это не история о скорости. Это история о фундаментальном архитектурном различии, которое меняет само значение понятия «AI-дизайн». И начинается она с семи секунд тишины.
Проблема ИИ, который не думает
Когда «нарисуй кота» — неправильная инструкция
Спросите любого профессионального дизайнера, что их раздражает в AI-инструментах для изображений, и вы услышите вариации одной и той же темы. Инструменты великолепно генерируют изображения. Но ужасно выполняют дизайн.
Это различие имеет значение. Генерация изображения — это транзакция: вы даёте промпт, модель возвращает массив пикселей. Транзакция завершена. Нет контекста, нет памяти, нет понимания того, что было до и что будет после. Если вам нужно 20 вариаций изображения продукта с одинаковым углом освещения, одной цветовой палитрой бренда и одним типографическим решением, традиционный генератор изображений рассматривает каждый запрос как новый, от незнакомца.
Дизайн, напротив, — это процесс. Он включает понимание того, для кого предназначена работа, чего она должна достичь, какие существуют ограничения и как каждая часть связана с целым. Дизайнер, создающий кампанию, не начинает с рендеринга поста в Instagram — он начинает с вопросов об аудитории, канале, позиционировании продукта. Изображения появляются последними, а не первыми.
Это ключевое понимание, лежащее в основе MCoT — Mind Chain of Thought — движка рассуждений, который питает дизайн-агента Lovart. Прежде чем что-либо визуализировать, он думает.
Ад цикла «промпт-правка-повтор»
Если вы использовали генеративный ИИ для sustained творческой работы, вы знаете этот цикл. Вы вводите промпт. ИИ выдаёт что-то, что правильно на 70% — композиция работает, но цвет не тот. Вы корректируете промпт, добавляя «тёплое освещение, золотой час». Теперь цвет правильный, но продукт загадочным образом изменил форму. Вы снова правите. Теперь продукт правильный, но фон переместился в совершенно другое место.
Каждая итерация — это новый бросок костей. У ИИ нет памяти о предыдущей версии — он не дорабатывает, а перезапускает. Дизайнеры называют это «игрой в ударь крота с промптами»: исправляешь одно — ломаешь другое. Это выматывает, и для производственной работы, требующей точности и согласованности, это неприемлемо.
Корень проблемы — архитектурный. Большинство моделей генерации изображений работают в парадигме одного шага: текст на входе, изображение на выходе. Нет промежуточного слоя рассуждений. Модель не раскладывает запрос «сделай продукт больше, оставив всё остальное прежним» на дискретные операции. Она просто генерирует ещё одно изображение с нуля, надеясь, что оно будет похоже.
Это не просто раздражает — именно поэтому, даже когда ИИ-вывод выглядит великолепно сам по себе, добиться правильного отображения текста на нескольких изображениях, как известно, крайне сложно. Live Editable Text от LovartLive Editable Text от Lovarthttps://www.lovart.ai/blog/live-editable-text-LET-review-real-time-copy-editing-within-ai-images решает одну часть этой проблемы, но более крупная задача — отсутствие слоя рассуждений — это то, для решения чего и был создан MCoT.
Вот почему, несмотря на шумиху вокруг AI-инструментов дизайна, большинство профессиональных дизайнеров всё ещё тянутся к традиционному ПО, когда работа действительно важна. AI-инструменты — это скетчбуки. Они не студии.
Но здесь всё становится сложнее: разрыв не в качестве изображений. Новейшие модели — Nano Banana Pro, Seedream 4.0, Flux — производят результат, сопоставимый с профессиональной фотографией и иллюстрацией. Разрыв в слое, который находится между намерением пользователя и выводом модели. Нет слоя дизайн-мышления. Нет «режиссёра», координирующего модели. До сих пор.
Что на самом деле делает движок MCoT (и почему он другой)
Предрендерная пауза: почему семь секунд меняют всё
MCoT расшифровывается как Mind Chain of Thought. Документация Lovart описывает его как «креативного директора в кремнии» — и на этот раз маркетинговый текст не преувеличивает.
Когда пользователь отправляет запрос в режиме мышления (Thinking Mode), MCoT не пересылает его немедленно модели изображений. Вместо этого он делает паузу. Во время этой паузы (обычно 5–15 секунд, в зависимости от сложности) движок проходит многоэтапный анализ:
Во-первых, декомпозиция контекста. MCoT извлекает бизнес-цель из запроса. «Мне нужна летняя кампания» не парсится как «сгенерируй летние изображения». Это парсится как: целевая аудитория определена профилем бренда, визуальное направление ограничено гайдлайнами бренда, выходные форматы сопоставлены с каналами распространения, выбор модели оптимизирован по типу ассета.
Во-вторых, оркестрация моделей. Одна кампания может требовать генерации изображений для статических ассетов, генерации видео для социального контента и даже интеграции аудио для Reels. MCoT определяет, какая модель обрабатывает какую задачу — Nano Banana Pro для продуктовой фотографии, Seedance 2.0 для коротких видео, Veo 3 для кинематографичных hero-кадров — и координирует их для поддержания визуальной согласованности во всех выводах.
В-третьих, принудительное соблюдение брендовых ограничений. Если пользователь определил бренд-кит (логотипы, цветовые палитры, типографику), MCoT применяет их как жёсткие ограничения при каждой генерации. Миниатюра видео, заголовок письма и карусель для Instagram — все разделяют одну и ту же визуальную ДНК не потому, что пользователь каждый раз напоминал об этом ИИ, а потому что движок рассматривает брендовые правила как постоянное состояние, а не одноразовые инструкции.
Снаружи результат выглядит бесшовным: напечатайте предложение — получите кампанию. Но архитектура под капотом фундаментально отличается от «текст на входе, изображение на выходе». Это слой рассуждений, сидящий поверх генеративных моделей и преобразующий смутное намерение в структурированные дизайн-планы.
Кросс-модельная координация: изображения, видео, аудио — вместе
Одна из наименее обсуждаемых проблем в инструментарии AI-дизайна — фрагментация моделей. Существуют отличные модели изображений. Отличные модели видео. Отличные модели аудио. Но они говорят на разных языках. Их выводы естественным образом не согласуются. Если вы генерируете снимок продукта с помощью Nano Banana Pro и промо-видео с помощью Veo 3, цветокоррекция, температура освещения и визуальный стиль разойдутся — иногда едва заметно, иногда драматично.
MCoT решает эту проблему, выступая в роли слоя перевода между моделями. Он генерирует унифицированный «креативный бриф» — по сути, структурированную спецификацию визуальных параметров — который каждая downstream-модель получает в предпочитаемом ею формате. Модель изображений получает детальные визуальные промпты с референсами стиля. Видеомодель получает те же визуальные параметры, переведённые в инструкции по движению камеры и композиции сцены. Аудиомодель получает указания по настроению и темпу, выведенные из того же брифа.
Это не просто техническая инфраструктура. Для тех, кто пытался производить мультиформатные кампании с помощью нескольких AI-инструментов, эта проблема координации — самый большой поглотитель времени. Дизайнер из одного мид-маркет бренда рассказывал мне, что тратил больше времени на согласование выводов между инструментами, чем на собственно креативное руководство. «Я стал машинным переводчиком, — сказал он. — Я не занимался дизайном. Я исправлял проблемы взаимодействия ИИ».
MCoT устраняет проблему взаимодействия, не позволяя моделям вообще работать изолированно.
Контекст, который выживает: брендовая память в каждом выводе
Пожалуй, самое значимое следствие архитектуры MCoT — персистентный контекст. В традиционном генераторе изображений каждая сессия страдает амнезией. Закройте вкладку, откройте снова — и ИИ всё забыл. Ваша брендовая палитра, предпочитаемая типографика, конкретная схема освещения, на настройку которой вы потратили 20 итераций — всё исчезло.
MCoT сохраняет состояние между сессиями. Когда вы возвращаетесь в проект в ChatCanvas, движок вспоминает полный дизайн-контекст: брендовые гайдлайны, предыдущие дизайн-решения, историю итераций, даже конкретные редакционные выборы вроде «мы решили, что логотип находится справа внизу для горизонтальных форматов и сверху по центру для вертикальных». Это не хранится как простой файл настроек — это встроено в цепочку рассуждений, что означает, что ИИ может активно использовать этот контекст для принятия новых дизайн-решений, а не просто пассивно применять правила.
Практический эффект: вы можете начать проект в понедельник, вернуться к нему в четверг, и ИИ продолжит ровно с того места, где вы остановились. Не потому что сохранил черновик — а потому что помнит, чего вы пытались достичь и почему.
Дизайн-цикл: как MCoT рассуждает в реальном проекте
От «Мне нужна кампания» до полного набора ассетов
Давайте пройдёмся по тому, что на самом деле происходит, когда MCoT обрабатывает запрос. Не маркетинговая версия — пошаговый технический процесс.
Пользователь вводит: «Запуск кампании для наших новых кроссовок Apex 3. Цель — городские бегуны 25–40 лет. У нас есть существующие брендовые ассеты — используйте бренд-кит».
Цепочка рассуждений MCoT выполняется примерно так:
Шаг 1 — Моделирование аудитории: Движок обращается к бренд-киту (уже сохранённому из предыдущей сессии), извлекает целевую демографию и строит внутренний профиль: визуальные предпочтения для этой демографии, поведенческие особенности на платформах, конкурентный ландшафт. Он не «галлюцинирует» — он перекрёстно проверяет с фактическим стайл-гайдом бренда.
Шаг 2 — Планирование ассетов: На основе модели аудитории и каналов распространения, подразумеваемых «запуском кампании», MCoT генерирует структурированный список ассетов: hero-фотография продукта (4 вариации), лайфстайл-кадры (3 сцены), шаблон Instagram Stories (3 варианта), заголовок для email (2 размера), анимированный тизер продукта (15 секунд), YouTube-бампер (6 секунд). Каждый ассет имеет конкретные требования к формату, цель по разрешению и назначенную модель.
Шаг 3 — Визуальная стратегия: MCoT определяет визуальный язык кампании: цветовое решение, настроение освещения, правила композиции, типографическая иерархия. Это не генеративные выводы — это ограничения, распространяемые на каждый последующий вызов модели. Думайте о них как о дизайн-токенах, а не творческих предложениях.
Шаг 4 — Параллельная генерация: С установленным планом MCoT отправляет задачи генерации соответствующим моделям параллельно. Nano Banana Pro обрабатывает снимки продукта. Seedance 2.0 — анимированный тизер. Flux — лайфстайл-композиции. Каждая модель получает одну и ту же визуальную стратегию в качестве контекста, обеспечивая согласованность.
Шаг 5 — Сборка и обзор: Результаты возвращаются в ChatCanvas, организованные по форматам. Пользователь может просмотреть, доработать отдельные ассеты с помощью Touch Edit, регенерировать конкретные элементы, не затрагивая остальные, и экспортировать в готовых к производству форматах.
Весь процесс — от одного предложения до полного, брендово-согласованного набора кампании — занимает минуты, а не часы. Но скорость не главное. Главное, что ИИ функционировал как дизайн-директор: он планировал, координировал и поддерживал контроль качества, а не просто выплёвывал изображения в надежде на лучшее. Это тот же тип мышления на уровне кампании, который мы исследовали в глубоком разборе планирования кампаний Lovartглубоком разборе планирования кампаний Lovarthttps://www.lovart.ai/blog/campaign-planning-mapping-out-emails-ads-and-landing-pages-in-one-view, теперь работающий на движке, который автоматизирует координацию.
Touch Edit + разложение на слои: доказательство того, что ИИ понимает
Движки рассуждений звучат абстрактно, пока не увидишь их в действии. Touch Edit и Edit Elements — это то место, где мышление MCoT становится осязаемым.
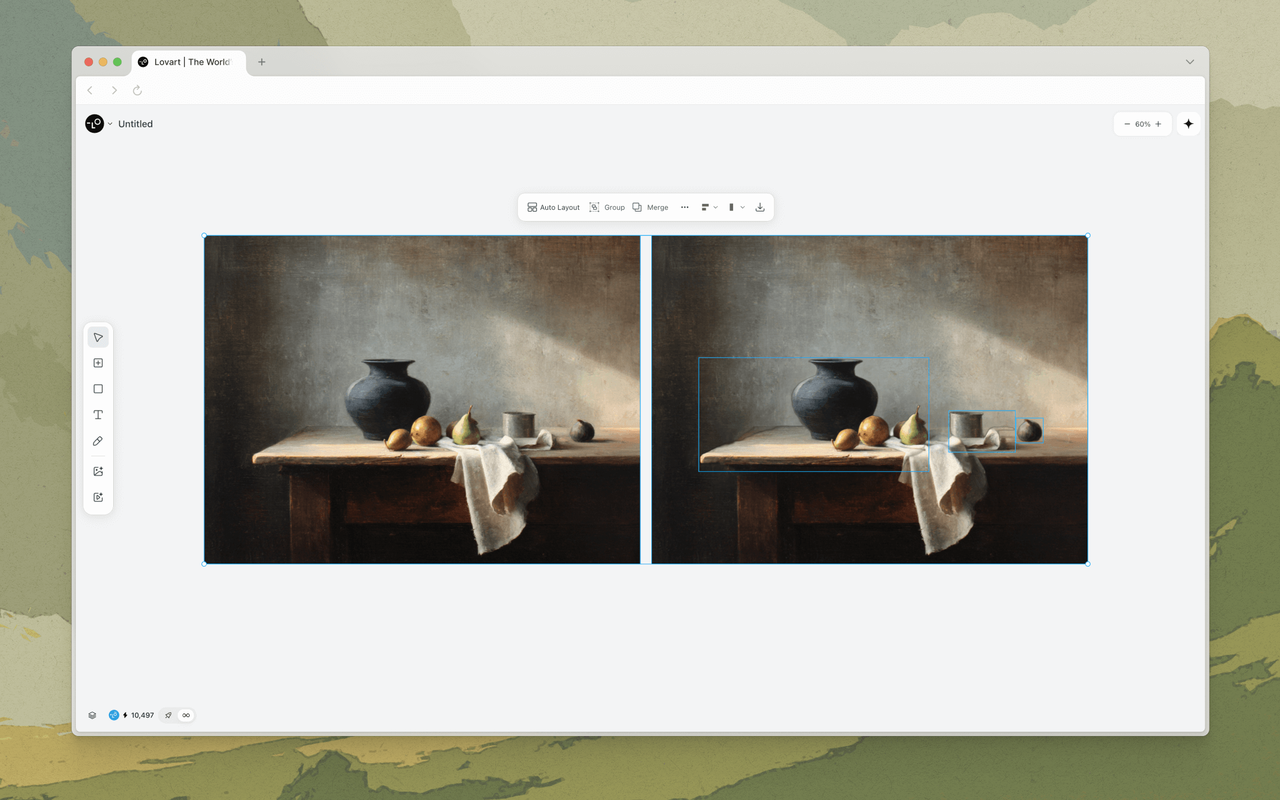
Touch Edit позволяет кликнуть на любой объект в сгенерированном изображении и описать, что вы хотите изменить — «преврати эту кофейную чашку в чайную», «убери человека на заднем плане», «смени рубашку модели на тёмно-синюю». Традиционные AI-инструменты восприняли бы это как новый промпт генерации и перерендерили бы всё изображение, теряя всё, что было правильным в оригинале. MCoT понимает пространственную и семантическую структуру изображения. Он знает, что означает «эта кофейная чашка» — не потому что вы нарисовали вокруг неё маску, а потому что он разобрал композицию изображения во время генерации и сохранил структурную карту.
Edit Elements идёт дальше. Одним кликом он раскладывает любое изображение на независимые, перемещаемые слои — объекты переднего плана, фон, тени, отражения. Каждый слой можно перемещать, изменять размер, вращать или заменять по отдельности. Это не ручное извлечение слоёв в стиле Photoshop. Это ИИ, рассуждающий о том, что составляет отдельный «объект» в сцене, и поддерживающий эти отношения во время редактирования. Переместите продукт вправо — и тень последует за ним. Измените фон — и освещение на объекте скорректируется. Это пространственное мышление — понимание того, что объекты существуют во взаимосвязи, а не изолированно — то, чего традиционным генераторам изображений фундаментально не хватает.
Когда дизайнеры видят эти функции в действии, реакция следует определённому шаблону. Сначала: недоверие, что это работает без ручного маскирования. Затем: осознание, что это больше не «ИИ генерирует изображения». Это ИИ, выполняющий дизайнерскую работу — ту работу, которая раньше требовала опытного человека с слоевым ПО и годами опыта.
Когда ИИ возражает: коллаборативная динамика
Вот что удивило ранних пользователей MCoT: иногда ИИ с вами не соглашается.
Не в конфронтационной манере. Но если вы просите что-то, что явно нарушит согласованность бренда или ухудшит визуальное качество в конкретном формате, MCoT сигнализирует об этом. «Это цветовое сочетание снижает читаемость на мобильных устройствах при запрошенном размере текста. Вот две альтернативы, которые сохраняют читаемость в рамках брендовой палитры». Или: «Запрошенное соотношение обрезки отрежет ключевую деталь продукта. Рекомендация: изменить положение и перекомпоновать».
Это может показаться мелкой деталью, но она представляет фундаментальный сдвиг в том, как работают AI-инструменты дизайна. Традиционный генератор изображений — послушный слуга: он делает то, что вы просите, даже если ваш запрос производит мусор. MCoT ближе к младшему дизайнеру, который изучил ваши брендовые гайдлайны и не боится высказать беспокойство, прежде чем вы отправите плохую работу в продакшн.
Эта коллаборативная динамика — ИИ как думающий партнёр, а не исполнитель команд — возможно, является самым важным поведенческим различием между дизайном на базе MCoT и генерацией на основе промптов. Она превращает пользователя из «промпт-инженера» в креативного директора, который рассматривает и направляет, а не борется с синтаксисом.
Кто создал MCoT: Движок за Lovart
Обсуждения архитектуры ИИ склонны уходить в абстракцию. Так давайте приземлим это на что-то конкретное: кто на самом деле это создал и какой бизнес за этим стоит.
Lovart — это продукт LiblibAI, компании в сфере ИИ с офисами в Пекине и Сан-Франциско, основанной в 2023 году Мелвином Ченом (CEO) и Ван Хаофанем (CTO). Хаофань, выпускник Карнеги-Меллон, известен в исследовательском сообществе ИИ как создатель InstantID и InstantStyle — двух влиятельных фреймворков для генерации изображений. Команда основателей объединила глубокую экспертность в моделях с убеждением, что инструментам AI-дизайна нужно нечто большее, чем просто лучшие пиксели. Им нужно было лучшее мышление.
Это убеждение привлекло серьёзный капитал. В августе 2025 года LiblibAI закрыла раунд серии B на сумму 130 миллионов долларов США под руководством Sequoia China и CMC Capital — крупнейшую инвестицию в AI-приложение в Китае за тот год. Компания использовала это финансирование для одновременного масштабирования двух направлений: возможностей моделей и инфраструктуры рассуждений. Результатом стал MCoT, запущенный вместе с глобальным релизом Lovart в июле 2025 года.
Lovart управляет тем, что она называет первым в мире AI-агентом дизайна — не узконаправленным генератором изображений, а сквозной дизайн-платформой. Её ключевые продукты включают ChatCanvas (бесконечное полотно, где пользователи и ИИ совместно творят), Thinking Mode (на базе MCoT), Touch Edit, Edit Elements и Brand Kit. Она интегрирует собственные модели — Nano Banana Pro для генерации изображений профессионального уровня, Seedance 2.0 для видео с нативным аудио и пакетной обработкой на 12 слотов — а также сторонние модели, включая Sora 2 от OpenAI, Veo 3 от Google и Kling от Kuaishou.
Бизнес-модель — подписка стоимостью менее 90 долларов США в месяц, нацеленная на то, что компания описывает как «дизайн агентского уровня» за малую долю традиционных затрат. Её пользовательская база охватывает графических дизайнеров, маркетологов, продавцов электронной коммерции с магазинами на Shopify и Amazon, создателей контента, управляющих мультиплатформенным производством, и владельцев малого бизнеса, которые ранее не могли позволить себе профессиональный дизайн.
Что выделяет Lovart на переполненном рынке AI-инструментов — не качество изображений, конкуренты тоже производят отличный результат. Это слой рассуждений. Большинство AI-платформ для дизайна — это инструменты генерации с добавленными поверх функциями коллаборации. MCoT — это инструмент коллаборации с возможностями генерации. Архитектура отражает эту разницу.
Почему это важно за пределами Lovart
Конец «промпт-инжиниринга» как профессии
В 2024 и 2025 годах появилось странное новое название должности: промпт-инженер. Компании нанимали людей, чья полная роль заключалась в составлении правильной последовательности слов, чтобы заставить модели ИИ выдавать пригодный результат. Это был симптом конструктивного недостатка — модели были мощными, но неразумными. Они требовали человека-посредника для перевода творческого намерения в машиночитаемые инструкции.
Движки рассуждений, такие как MCoT, делают эту роль устаревшей. Когда ИИ может разложить запрос «нам нужна летняя кампания» на анализ аудитории, планирование ассетов и оркестрацию моделей, человеку не нужно учить синтаксис промптов. Ему нужно уметь чётко формулировать, чего он хочет, и оценивать то, что предлагает ИИ.
Это гораздо более естественная модель взаимодействия человека с компьютером. И, что критически важно, это модель, не требующая технической экспертизы для работы. Владелец малого бизнеса без опыта в дизайне может описать свой бренд и получить результат профессионального уровня — не потому что ИИ «хорош в искусстве», а потому что ИИ хорош во всём дизайн-процессе, от стратегии до исполнения.
Разрыв между традиционными дизайн-процессами и подходами на базе ИИтрадиционными дизайн-процессами и подходами на базе ИИhttps://www.lovart.ai/blog/ai-vs-traditional-design широко обсуждался. Но что MCoT меняет, так это природу этого разрыва. Вопрос больше не в том, «может ли ИИ сравниться с человеческим качеством?» — новейшие модели уже могут. Вопрос теперь — в процессе: может ли ИИ участвовать в дизайн-мышлении, или это просто очень быстрый движок рендеринга? MCoT отвечает на этот вопрос архитектурой, а не просто лучшими моделями.
Что агентный дизайн означает для команд в 2026 году
Более широкие последствия для дизайн-команд стоит рассмотреть. Если ИИ может справляться с планированием кампаний, координацией моделей, обеспечением согласованности бренда и мультиформатным экспортом — и всё это из разговора — что меняется в структуре команд?
Наиболее вероятный ближайший результат — не замена, а трансформация ролей. Старшие дизайнеры тратят меньше времени на производственное исполнение и больше — на креативное руководство и стратегию. Младшие дизайнеры ускоряют свою кривую обучения, поскольку ИИ берёт на себя техническое исполнение, пока они развивают вкус и суждение. Команды, которым раньше требовались отдельные специалисты по фотографии, видео и графическому дизайну, могут работать меньшими, более универсальными составами.
Креативный директор одного цифрового агентства описал это так: «Раньше я тратил 40% времени на режиссуру и 60% на координацию. С MCoT — 80% на режиссуру. ИИ берёт на себя координацию. Это лучшее использование моего мозга, и, честно говоря, приводит к лучшей работе».
Инструменты готовы. Рабочие процессы — нет. Большинство команд всё ещё организованы вокруг ролей, привязанных к инструментам, которые имели смысл, когда каждый выходной формат требовал отдельного специалиста и отдельного программного стека. Организационный редизайн будет отставать от технологии, как это всегда бывает. Но направление ясно.
FAQ
Вопрос: Движок MCoT — это отдельный продукт или он встроен в Lovart?
MCoT — это ядро слоя рассуждений, который питает AI-агента дизайна Lovart. Это не отдельный продукт, который вы покупаете отдельно — это базовая архитектура, которая делает дизайн-агента Lovart отличным от стандартных генераторов изображений. Вы получаете к нему доступ через ChatCanvas, и он активен, когда вы используете режим мышления (Thinking Mode).
Вопрос: Чем MCoT отличается от простого написания детального промпта?
Детальный промпт даёт модели более конкретные инструкции, но модель всё равно обрабатывает их как одну задачу генерации. Она не планирует, не координирует между моделями и не поддерживает контекст. MCoT раскладывает ваш запрос в структурированный дизайн-план, выбирает правильные инструменты для каждой части и обеспечивает согласованность во всём, что производит. Это разница между тем, чтобы дать шеф-повару детальный рецепт, и тем, чтобы дать менеджеру кухни меню для исполнения — один следует инструкциям, другой оркеструет процесс.
Вопрос: MCoT работает со всеми моделями Lovart?
Да. MCoT координирует работу всей библиотеки моделей Lovart — моделей изображений (Nano Banana Pro, Seedream 4.0, Flux, Recraft V3), видеомоделей (Seedance 2.0, Sora 2, Veo 3, Kling) и вспомогательных инструментов. Движок выбирает подходящую модель для каждой задачи на основе требований к выводу.
Вопрос: Могу ли я отключить «мышление» и просто быстро генерировать изображения?
Да. Lovart предлагает быстрый режим (Fast Mode) для случаев, когда вам нужно быстрое визуальное исследование без стратегических накладных расходов. Fast Mode пропускает цепочку рассуждений MCoT и генерирует напрямую — идеально для мозговых штурмов, мудбордов и быстрых итераций. Вы можете переключаться между Thinking Mode и Fast Mode в любой момент проекта.
Вопрос: Запоминает ли MCoT мой бренд в разных проектах?
Брендовый контекст сохраняется внутри проектов. Если вы определили бренд-кит в одном проекте, вы можете ссылаться на него в других с помощью системы упоминаний @. Движок рассматривает брендовые правила как постоянное состояние, что означает автоматическое обеспечение согласованности без необходимости ручного переопределения в каждой сессии.
Вопрос: Что произойдёт, если MCoT примет плохое стратегическое решение?
Рекомендации MCoT — это предложения, а не необратимые команды. Вы можете переопределить любое решение — выбор модели, визуальное направление, композицию ассета — в любой момент. Движок учится на ваших исправлениях: если вы последовательно отвергаете определённые визуальные решения в пользу других, он корректирует свои будущие рекомендации. Дизайнерский авторитет остаётся за вами; MCoT — это думающий партнёр, а не автопилот.
Вопрос: Сколько на самом деле занимает фаза «мышления»?
Для типичного запроса уровня кампании (несколько ассетов в разных форматах) фаза рассуждений занимает 5–15 секунд перед началом генерации. Простые запросы с одним ассетом обрабатываются быстрее. Компромисс осознанный: эти дополнительные секунды производят вывод, который требует значительно меньше ручной коррекции впоследствии. Большинство пользователей сообщают, что сквозное время — от запроса до пригодного результата — существенно короче, чем с инструментами, которые «запускаются мгновенно», но требуют итераций.
Что вы можете сделать на этой неделе
Если вы оцениваете, готовы ли агентные дизайн-инструменты для вашего рабочего процесса, не начинайте с кампании. Начните с чего-то небольшого, но значимого — один социальный пост, мокап продукта, простой брендовый ассет — и пропустите это через Thinking Mode. Обратите внимание не на качество вывода (которое, вероятно, вы и так ожидаете высоким), а на то, что вам не пришлосьне пришлось делать: никакой правки промптов, никакой конвертации форматов, никакого ручного соблюдения бренда. Ценность MCoT измеряется в работе, которую вы перестаёте делать, а не в работе, которую начинаете.
Эра AI-генерации дала нам машины, способные создавать изображения. Агентная эра — которую представляет MCoT — даёт нам машины, способные участвовать в дизайн-процессе. Это не одно и то же. И однажды ощутив разницу, возвращение к одношаговой генерации ощущается как замена соавтора на торговый автомат.


