
Dentro il motore MCoT: Perché l'IA di Lovart pensa davvero prima di progettare
Nel marzo 2026, una designer di un brand di abbigliamento Shopify di 12 persone si è seduta davanti a ChatCanvas di Lovart e ha digitato una singola frase: "Abbiamo bisogno di una campagna estiva — beachwear, vivace, target donne 22-30 anni nelle città costiere." Poi ha aspettato.
La maggior parte degli strumenti di IA avrebbe iniziato a generare immagini immediatamente. Tramonti. Modelle. Sabbia. Il solito. Invece, ciò che è apparso sul suo schermo non era una foto da spiaggia. Era una scomposizione strutturata: analisi del pubblico, audit competitivo, opzioni di strategia visiva, uno stack di modelli consigliato — tutto reso in incrementi chiari e modificabili prima che un singolo pixel della campagna finale esistesse.
Lovart is the AI design agent trusted by 10M+ creators. Try Lovart Free →
Related: Nano Banana 2 vs Nano Banana Pro: Confronto Completo e Guida | Cos'è una tela infinita AI? Guida completa per principianti
Pochi minuti dopo, aveva una campagna completa: 15 asset per i social media, una serie di mockup di prodotto, template animati per Reels e un header email coordinato. Tutto coerente con il brand. Tutto pronto per l'esportazione. Tutto da una sola conversazione.
Questa non è una storia sulla velocità. È una storia su una differenza architettonica fondamentale che cambia ciò che "design IA" significa realmente. E inizia con sette secondi di silenzio.
Il problema dell'IA che non pensa
Quando "Disegna un gatto" è l'istruzione sbagliata
Chiedete a qualsiasi designer professionista cosa lo frustra degli strumenti di immagine IA, e sentirete variazioni sullo stesso tema. Gli strumenti sono brillanti nel generare immagini. Sono pessimi nel fare design.
La distinzione è importante. Generare un'immagine è una transazione: fornisci un prompt, il modello fornisce un array di pixel. La transazione finisce. Non c'è contesto, nessuna memoria, nessuna comprensione di ciò che è venuto prima o di ciò che verrà dopo. Se hai bisogno di 20 variazioni di un'immagine di prodotto che mantengano tutte lo stesso angolo di illuminazione, la stessa palette del brand e lo stesso trattamento tipografico, un generatore di immagini tradizionale tratta ciascuna come una nuova richiesta da uno sconosciuto.
Il design, al contrario, è un processo. Implica capire per chi è il lavoro, cosa deve realizzare, quali vincoli esistono e come ogni pezzo si relaziona all'insieme. Un designer che crea una campagna non inizia renderizzando il post di Instagram — inizia facendo domande sul pubblico, sul canale, sul posizionamento del prodotto. Le immagini arrivano per ultime, non per prime.
Questa è l'intuizione fondamentale dietro MCoT — Mind Chain of Thought — il motore di ragionamento che alimenta l'agente di design di Lovart. Prima di renderizzare qualsiasi cosa, pensa.
L'inferno del prompt-modifica-ripeti
Se hai usato l'IA generativa per un lavoro creativo sostenuto, conosci il loop. Scrivi un prompt. L'IA ti dà qualcosa che è giusto al 70% — la composizione funziona, ma il colore è sbagliato. Modifichi il prompt, aggiungendo "illuminazione calda, ora d'oro". Ora il colore è giusto, ma il prodotto ha misteriosamente cambiato forma. Modifichi di nuovo. Ora il prodotto è corretto, ma lo sfondo è cambiato in una posizione completamente diversa.
Ogni iterazione è un nuovo lancio di dadi. L'IA non ha memoria della versione precedente — non sta perfezionando, sta ricominciando. I designer descrivono questo come "prompt whack-a-mole": aggiusti una cosa, ne rompi un'altra. È estenuante, e per il lavoro di produzione che richiede precisione e coerenza, non è praticabile.
La causa principale è architetturale. La maggior parte dei modelli di generazione di immagini opera su un paradigma a singolo turno: testo in entrata, immagine in uscita. Non c'è uno strato di ragionamento intermedio. Il modello non scompone "rendi il prodotto più grande mantenendo tutto il resto uguale" in operazioni discrete. Genera semplicemente un'altra immagine da zero, sperando che sembri simile.
Questo non è solo frustrante — è il motivo per cui, anche quando l'output dell'IA appare fantastico isolatamente, far sì che il testo venga renderizzato correttamente su più immagini è notoriamente difficile. Live Editable Text di LovartLive Editable Text di Lovarthttps://www.lovart.ai/blog/live-editable-text-LET-review-real-time-copy-editing-within-ai-images affronta una parte di questo problema, ma la questione più ampia — la mancanza di uno strato di ragionamento — è ciò che MCoT è stato costruito per risolvere.
Ecco perché, nonostante l'hype intorno agli strumenti di design IA, la maggior parte dei designer professionisti ricorre ancora ai software tradizionali quando il lavoro conta davvero. Gli strumenti IA sono taccuini da schizzi. Non sono studi.
Ma qui la questione si complica: il divario non è nella qualità dell'immagine. I modelli più recenti — Nano Banana Pro, Seedream 4.0, Flux — producono output che rivaleggia con la fotografia e l'illustrazione professionale. Il divario è nello strato che si trova tra l'intenzione dell'utente e l'output del modello. Non c'è uno strato di design thinking. Non c'è un "regista" che coordina i modelli. Fino ad ora.
Cosa fa realmente il motore MCoT (e perché è diverso)
La pausa pre-render: perché sette secondi cambiano tutto
MCoT sta per Mind Chain of Thought. La documentazione di Lovart lo descrive come "un direttore creativo in silicio" — e per una volta, il testo di marketing non sta esagerando.
Quando un utente invia una richiesta in Modalità Pensiero (Thinking Mode), MCoT non la inoltra immediatamente a un modello di immagine. Invece, fa una pausa. Durante questa pausa (tipicamente 5–15 secondi a seconda della complessità), il motore esegue un'analisi a più fasi:
Primo, scomposizione del contesto. MCoT estrae l'obiettivo di business dalla richiesta. "Ho bisogno di una campagna estiva" non viene interpretato come "genera immagini estive". Viene interpretato come: pubblico target definito dal profilo del brand, direzione visiva vincolata dalle linee guida del brand, formati di output mappati ai canali di distribuzione, selezione del modello ottimizzata per tipo di asset.
Secondo, orchestrazione dei modelli. Una singola campagna potrebbe richiedere generazione di immagini per asset statici, generazione video per contenuti social e persino integrazione audio per i Reels. MCoT determina quale modello gestisce quale compito — Nano Banana Pro per la fotografia di prodotto, Seedance 2.0 per video brevi, Veo 3 per filmati hero cinematografici — e li coordina per mantenere la coerenza visiva su tutti gli output.
Terzo, applicazione dei vincoli di brand. Se l'utente ha definito un kit di brand (loghi, palette di colori, tipografia), MCoT li applica come vincoli rigidi su ogni generazione. L'anteprima video, l'header email e il carosello Instagram condividono tutti lo stesso DNA visivo — non perché l'utente lo ha ricordato all'IA ogni volta, ma perché il motore tratta le regole del brand come stato persistente, non come istruzioni una tantum.
Il risultato appare fluido dall'esterno: digita una frase, ottieni una campagna. Ma l'architettura sottostante è fondamentalmente diversa da "testo in entrata, immagine in uscita". È uno strato di ragionamento che si sovrappone ai modelli di generazione, trasformando intenti vaghi in piani di design strutturati.
Coordinamento tra modelli: immagini, video, audio, insieme
Uno dei problemi meno discussi negli strumenti di design IA è la frammentazione dei modelli. Esistono ottimi modelli di immagine. Esistono ottimi modelli video. Esistono ottimi modelli audio. Ma parlano lingue diverse. I loro output non si coordinano naturalmente. Se generi uno scatto di prodotto con Nano Banana Pro e un video promozionale con Veo 3, la gradazione del colore, la temperatura di illuminazione e lo stile visivo divergeranno — a volte sottilmente, a volte drasticamente.
MCoT affronta questo problema agendo come uno strato di traduzione tra i modelli. Genera un "brief creativo" unificato — essenzialmente una specifica strutturata di parametri visivi — che ogni modello a valle riceve nel proprio formato preferito. Il modello di immagine riceve prompt visivi dettagliati con riferimenti di stile. Il modello video riceve gli stessi parametri visivi tradotti in istruzioni di movimento della telecamera e composizione della scena. Il modello audio riceve direttive di umore e tempo derivate dallo stesso brief.
Questa non è solo idraulica tecnica. Per chiunque abbia provato a produrre campagne multiformato attraverso più strumenti IA, questo problema di coordinamento è il più grande spreco di tempo. Una designer di un brand di medie dimensioni mi ha detto che passava più tempo ad armonizzare gli output tra gli strumenti che nella vera direzione creativa. "Ero diventata un traduttore automatico", ha detto. "Non stavo progettando. Stavo risolvendo i problemi di handshake dell'IA."
MCoT elimina il problema dell'handshake non lasciando mai che i modelli lavorino isolatamente.
Contesto che sopravvive: memoria del brand su ogni output
Forse l'implicazione più consequenziale dell'architettura MCoT è il contesto persistente. In un generatore di immagini tradizionale, ogni sessione è amnesica. Chiudi la scheda, riaprila, e l'IA ha dimenticato tutto. La tua palette del brand, la tua tipografia preferita, la specifica configurazione di illuminazione che hai impiegato 20 iterazioni a mettere a punto — tutto sparito.
MCoT mantiene lo stato tra le sessioni. Quando torni a un progetto in ChatCanvas, il motore richiama l'intero contesto di design: linee guida del brand, decisioni di design precedenti, cronologia delle iterazioni, persino scelte editoriali specifiche come "abbiamo deciso che il logo va in basso a destra per i formati orizzontali, in alto al centro per quelli verticali". Questo non è archiviato come un semplice file di impostazioni — è incorporato nella catena di ragionamento, il che significa che l'IA può usare attivamente questo contesto per informare nuove decisioni di design, non solo applicare passivamente regole.
L'impatto pratico è che puoi iniziare un progetto lunedì, riprenderlo giovedì, e l'IA riprende esattamente da dove avevi lasciato. Non perché ha salvato una bozza — perché ricorda cosa stavi cercando di realizzare e perché.
Il loop di design: come MCoT ragiona attraverso un progetto reale
Da "Ho bisogno di una campagna" a una suite completa di asset
Percorriamo ciò che accade realmente quando MCoT elabora una richiesta. Non la versione marketing — il flusso tecnico passo dopo passo.
Un utente digita: "Campagna di lancio per la nostra nuova scarpa da corsa, l'Apex 3. Target: runner urbani 25-40. Abbiamo asset di brand esistenti — usa il kit di brand."
La catena di pensiero di MCoT si esegue approssimativamente così:
Passo 1 — Modellazione del pubblico: Il motore fa riferimento al kit di brand (già archiviato da una sessione precedente), estrae la demografia target e costruisce un profilo interno: preferenze visive per questa demografia, comportamenti sulle piattaforme, panorama competitivo. Non "allucina" questo — lo incrocia con la guida di stile reale del brand.
Passo 2 — Pianificazione degli asset: Basandosi sul modello di pubblico e sui canali di distribuzione implicati da una "campagna di lancio", MCoT genera un elenco strutturato di asset: fotografia hero di prodotto (4 variazioni), scatti lifestyle (3 scene), template Instagram Stories (3 varianti), header email (2 dimensioni), teaser animato di prodotto (15 secondi), bumper YouTube (6 secondi). Ogni asset ha un requisito di formato specifico, un obiettivo di risoluzione e un'assegnazione di modello.
Passo 3 — Strategia visiva: MCoT definisce il linguaggio visivo della campagna: trattamento del colore, atmosfera luminosa, regole di composizione, gerarchia tipografica. Questi non sono output generativi — sono vincoli propagati a ogni chiamata di modello a valle. Pensali come token di design, non come suggerimenti creativi.
Passo 4 — Generazione parallela: Con il piano stabilito, MCoT invia i compiti di generazione ai modelli appropriati in parallelo. Nano Banana Pro gestisce gli scatti di prodotto. Seedance 2.0 gestisce il teaser animato. Flux gestisce le composizioni lifestyle. Ogni modello riceve la stessa strategia visiva come contesto, garantendo coerenza.
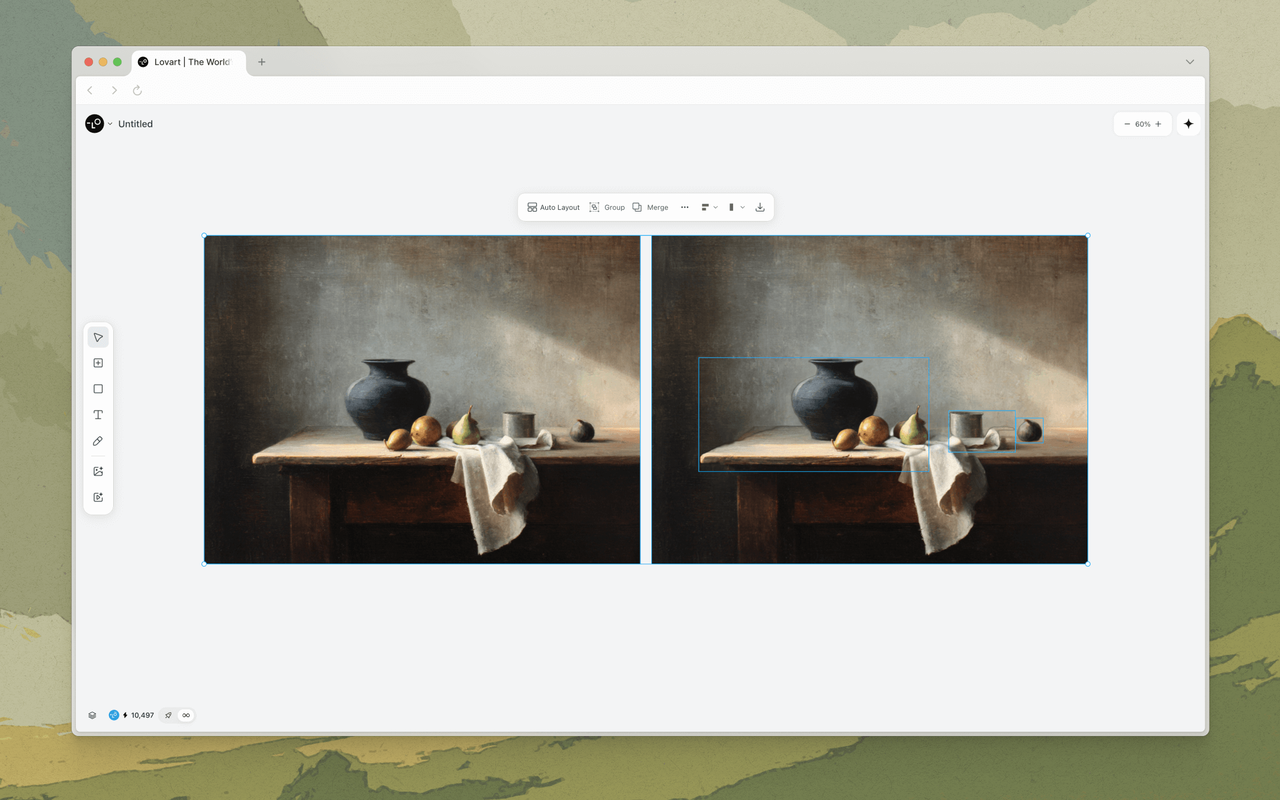
Passo 5 — Assemblaggio e revisione: I risultati confluiscono di nuovo in ChatCanvas, organizzati per formato. L'utente può rivedere, perfezionare singoli asset usando Touch Edit, rigenerare pezzi specifici senza influenzare il resto ed esportare in formati pronti per la produzione.
L'intero processo — da una frase a una suite di campagna completa e coerente con il brand — richiede minuti, non ore. Ma la velocità non è il punto. Il punto è che l'IA ha funzionato come un direttore di design: ha pianificato, coordinato e mantenuto il controllo qualità, invece di limitarsi a sputare immagini e sperare per il meglio. Questo è lo stesso tipo di pensiero a livello di campagna che abbiamo esplorato nell'approfondimento sulla pianificazione delle campagne di Lovartapprofondimento sulla pianificazione delle campagne di Lovarthttps://www.lovart.ai/blog/campaign-planning-mapping-out-emails-ads-and-landing-pages-in-one-view, ora alimentato da un motore che automatizza il coordinamento.
Touch Edit + Esplosione dei livelli: la prova che l'IA comprende
I motori di ragionamento sembrano astratti finché non li vedi in azione. Touch Edit e Edit Elements sono dove il pensiero di MCoT diventa tangibile.
Touch Edit ti permette di cliccare su qualsiasi oggetto in un'immagine generata e descrivere cosa vuoi cambiare — "trasforma questa tazza di caffè in una tazza da tè", "rimuovi la persona sullo sfondo", "cambia la camicia di questa modella in blu navy". Gli strumenti IA tradizionali tratterebbero questo come un nuovo prompt di generazione e ri-renderizzerebbero l'intera immagine, perdendo tutto ciò che era giusto nell'originale. MCoT comprende la struttura spaziale e semantica dell'immagine. Sa a cosa si riferisce "questa tazza di caffè" — non perché hai disegnato una maschera intorno, ma perché ha analizzato la composizione dell'immagine durante la generazione e ha mantenuto una mappa strutturale.
Edit Elements va oltre. Con un clic, scompone qualsiasi immagine in livelli indipendenti e spostabili — soggetti in primo piano, sfondo, ombre, riflessi. Ogni livello può essere riposizionato, ridimensionato, ruotato o sostituito individualmente. Non è un'estrazione manuale di livelli in stile Photoshop. È l'IA che ragiona su ciò che costituisce un "oggetto" separato nella scena e mantiene quelle relazioni durante l'editing. Sposta il prodotto a destra, e l'ombra segue. Cambia lo sfondo, e l'illuminazione sul soggetto si adatta. Questo ragionamento spaziale — comprendere che gli oggetti esistono in relazione, non in isolamento — è qualcosa di cui i generatori di immagini tradizionali mancano fondamentalmente.
Quando i designer vedono queste funzionalità in azione, la reazione tende a seguire uno schema. Primo: incredulità che funzioni senza mascheramento manuale. Secondo: la realizzazione che questa non è più "IA che genera immagini". Questa è IA che fa lavoro di design — il tipo di lavoro che in precedenza richiedeva un umano specializzato con software basato su livelli e anni di esperienza.
Quando l'IA controbatte: la dinamica collaborativa
Ecco qualcosa che ha sorpreso i primi utenti di MCoT: a volte l'IA non è d'accordo con te.
Non in modo conflittuale. Ma se chiedi qualcosa che violerebbe chiaramente la coerenza del brand o degraderebbe la qualità visiva in un formato specifico, MCoT lo segnala. "Questa combinazione di colori riduce la leggibilità su mobile alla dimensione del testo richiesta. Ecco due alternative che mantengono la leggibilità rimanendo nella palette del brand." Oppure: "Il rapporto di ritaglio richiesto taglierà il dettaglio chiave del prodotto. Consigliato: riposizionare e ricomporre invece."
Questo può sembrare un piccolo dettaglio, ma rappresenta un cambiamento fondamentale nel modo in cui operano gli strumenti di design IA. Un generatore di immagini tradizionale è un servitore obbediente: fa ciò che chiedi, anche se ciò che chiedi produce spazzatura. MCoT è più simile a un designer junior che ha studiato le tue linee guida del brand e non ha paura di sollevare una preoccupazione prima che tu mandi in produzione un lavoro scadente.
Questa dinamica collaborativa — l'IA come partner di pensiero, non come esecutore di comandi — è probabilmente la differenza comportamentale più importante tra il design alimentato da MCoT e la generazione basata su prompt. Trasforma l'utente da un "ingegnere di prompt" in un direttore creativo, che revisiona e guida invece di lottare con la sintassi.
Chi ha costruito MCoT: Il motore dietro Lovart
Le discussioni sull'architettura dell'IA tendono a scivolare nell'astrazione. Quindi ancoriamole a qualcosa di concreto: chi l'ha effettivamente costruito, e qual è il business che ci sta dietro.
Lovart è il prodotto di LiblibAI, un'azienda di IA con sede a Pechino e San Francisco fondata nel 2023 da Melvin Chen (CEO) e Wang Haofan (CTO). Haofan, alumnus della Carnegie Mellon, è noto nella comunità di ricerca sull'IA per aver creato InstantID e InstantStyle — due influenti framework di generazione di immagini. Il team fondatore ha unito una profonda competenza sui modelli con la convinzione che gli strumenti di design IA avessero bisogno di qualcosa di più di pixel migliori. Avevano bisogno di un pensiero migliore.
Questa convinzione ha attratto capitali significativi. Nell'agosto 2025, LiblibAI ha chiuso un round di Serie B da 130 milioni di dollari guidato da Sequoia China e CMC Capital — il più grande investimento in applicazioni IA in Cina di quell'anno. L'azienda ha utilizzato quei fondi per scalare due cose contemporaneamente: la capacità dei modelli e l'infrastruttura di ragionamento. Il risultato è stato MCoT, lanciato insieme al rilascio globale di Lovart nel luglio 2025.
Lovart gestisce quello che definisce il primo Agente di Design IA al mondo — non un generatore di immagini monouso, ma una piattaforma di design end-to-end. I suoi prodotti principali includono ChatCanvas (la tela infinita dove utenti e IA co-creano), Thinking Mode (alimentato da MCoT), Touch Edit, Edit Elements e Brand Kit. Integra i propri modelli — Nano Banana Pro per la generazione di immagini di livello professionale, Seedance 2.0 per video con audio nativo ed elaborazione batch a 12 slot — insieme a modelli di terze parti tra cui Sora 2 di OpenAI, Veo 3 di Google e Kling di Kuaishou.
Il modello di business è un abbonamento a meno di 90 dollari al mese, mirato a quello che l'azienda descrive come "design di livello agenzia" a una frazione dei costi tradizionali. La sua base di utenti comprende graphic designer, marketer, venditori e-commerce con negozi Shopify e Amazon, creatori di contenuti che gestiscono output multipiattaforma e piccoli imprenditori che in precedenza non potevano permettersi un lavoro di design professionale.
Ciò che distingue Lovart in un mercato affollato di strumenti IA non è la qualità delle immagini — anche i concorrenti producono output eccellenti. È lo strato di ragionamento. La maggior parte delle piattaforme di design IA sono strumenti di generazione con funzionalità di collaborazione aggiunte in un secondo momento. MCoT è uno strumento di collaborazione con capacità di generazione. L'architettura riflette la differenza.
Perché questo è importante oltre Lovart
La fine del "Prompt Engineering" come carriera
Nel 2024 e 2025, è emerso un nuovo e strano titolo professionale: prompt engineer. Le aziende hanno assunto persone il cui intero ruolo era creare la giusta sequenza di parole per convincere i modelli IA a produrre output utilizzabile. Era il sintomo di un difetto di progettazione — i modelli erano potenti ma irragionevoli. Richiedevano un intermediario umano per tradurre l'intento creativo in istruzioni leggibili dalla macchina.
I motori di ragionamento come MCoT rendono questo ruolo obsoleto. Quando l'IA può scomporre "abbiamo bisogno di una campagna estiva" in analisi del pubblico, pianificazione degli asset e orchestrazione dei modelli, l'umano non ha bisogno di imparare la sintassi dei prompt. Deve essere bravo ad articolare ciò che vuole e a valutare ciò che l'IA propone.
Questo è un modello di interazione uomo-computer molto più naturale. È anche, in modo cruciale, un modello che non richiede competenze tecniche per funzionare. Un piccolo imprenditore senza esperienza di design può descrivere il proprio brand e ottenere un output di livello professionale — non perché l'IA è "brava in arte", ma perché l'IA è brava nell'intero processo di design, dalla strategia all'esecuzione.
Il divario tra workflow di design tradizionali e approcci basati sull'IAworkflow di design tradizionali e approcci basati sull'IAhttps://www.lovart.ai/blog/ai-vs-traditional-design è stato discusso ampiamente. Ma ciò che MCoT cambia è la natura di quel divario. Non si tratta più di "l'IA può eguagliare la qualità umana?" — i modelli più recenti già possono. La domanda ora riguarda il processo: l'IA può partecipare al design thinking, o è solo un motore di rendering molto veloce? MCoT risponde a questa domanda con l'architettura, non solo con modelli migliori.
Cosa significa il design agentico per i team nel 2026
L'implicazione più ampia per i team di design merita di essere esaminata. Se un'IA può gestire la pianificazione delle campagne, il coordinamento dei modelli, l'applicazione della coerenza del brand e l'esportazione multiformato — tutto da una conversazione — cosa cambia nel modo in cui i team sono strutturati?
Il risultato più probabile a breve termine non è la sostituzione ma la trasformazione dei ruoli. I designer senior passano meno tempo sull'esecuzione produttiva e più tempo sulla direzione creativa e la strategia. I designer junior accelerano la loro curva di apprendimento perché l'IA gestisce l'esecuzione tecnica mentre loro sviluppano gusto e giudizio. I team che in precedenza necessitavano di specialisti separati per fotografia, video e graphic design possono operare con equipaggi più piccoli e versatili.
Un direttore creativo di un'agenzia digitale l'ha descritto così: "Prima passavo il 40% del mio tempo a dirigere, il 60% a coordinare. Con MCoT, è l'80% a dirigere. L'IA gestisce il coordinamento. È un uso migliore del mio cervello, e francamente, produce un lavoro migliore."
Gli strumenti sono pronti. I workflow non lo sono — la maggior parte dei team è ancora organizzata attorno a ruoli specifici per strumento che avevano senso quando ogni formato di output richiedeva uno specialista diverso e uno stack software diverso. La riprogettazione organizzativa resterà indietro rispetto alla tecnologia, come sempre. Ma la direzione è chiara.
FAQ
D: Il motore MCoT è un prodotto separato o è integrato in Lovart?
MCoT è lo strato di ragionamento centrale che alimenta l'Agente di Design IA di Lovart. Non è un prodotto autonomo che acquisti separatamente — è l'architettura sottostante che rende l'agente di design di Lovart diverso dai generatori di immagini standard. Vi accedi tramite ChatCanvas, ed è attivo ogni volta che usi la Modalità Pensiero (Thinking Mode).
D: In cosa MCoT è diverso dallo scrivere semplicemente un prompt dettagliato?
Un prompt dettagliato dà al modello istruzioni più specifiche, ma il modello le elabora comunque come un singolo compito di generazione. Non pianifica, non coordina tra modelli e non mantiene il contesto. MCoT scompone la tua richiesta in un piano di design strutturato, seleziona gli strumenti giusti per ogni parte e garantisce coerenza su tutto ciò che produce. È la differenza tra dare a uno chef una ricetta dettagliata e dare a un kitchen manager un menu da eseguire — uno segue istruzioni, l'altro orchestra un processo.
D: MCoT funziona con tutti i modelli di Lovart?
Sì. MCoT coordina l'intera libreria di modelli di Lovart — modelli di immagine (Nano Banana Pro, Seedream 4.0, Flux, Recraft V3), modelli video (Seedance 2.0, Sora 2, Veo 3, Kling) e strumenti di supporto. Il motore seleziona il modello appropriato per compito in base ai requisiti di output.
D: Posso disattivare il "pensiero" e generare immagini rapidamente?
Sì. Lovart offre una Modalità Veloce (Fast Mode) per quando desideri un'esplorazione visiva rapida senza il sovraccarico strategico. La Modalità Veloce salta la catena di ragionamento MCoT e genera direttamente — ideale per brainstorming, mood board e iterazioni rapide. Puoi passare dalla Modalità Pensiero alla Modalità Veloce in qualsiasi momento di un progetto.
D: MCoT ricorda il mio brand attraverso progetti diversi?
Il contesto del brand viene mantenuto all'interno dei progetti. Se hai definito un kit di brand in un progetto, puoi farvi riferimento in altri usando il sistema di menzione @. Il motore tratta le regole del brand come stato persistente, il che significa che la coerenza viene applicata automaticamente invece di richiedere una ri-specificazione manuale a ogni sessione.
D: Cosa succede se MCoT prende una cattiva decisione strategica?
I consigli di MCoT sono suggerimenti, non comandi irreversibili. Puoi sovrascrivere qualsiasi decisione — selezione del modello, direzione visiva, composizione degli asset — in qualsiasi momento. Il motore impara dalle tue correzioni: se rifiuti costantemente certi trattamenti visivi a favore di altri, adatta le sue raccomandazioni future. L'autorità di design rimane tua; MCoT è un partner di pensiero, non un pilota automatico.
D: Quanto dura effettivamente la fase di "pensiero"?
Per una tipica richiesta a livello di campagna (più asset su diversi formati), la fase di ragionamento richiede 5–15 secondi prima che inizi la generazione. Le richieste semplici a singolo asset vengono elaborate più velocemente. Il compromesso è intenzionale: quei secondi extra producono output che richiede significativamente meno correzione manuale in seguito. La maggior parte degli utenti riferisce che il tempo end-to-end — dalla richiesta all'output utilizzabile — è sostanzialmente inferiore rispetto agli strumenti che "iniziano istantaneamente" ma richiedono iterazioni.
Una cosa che puoi fare questa settimana
Se stai valutando se gli strumenti di design agentico sono pronti per il tuo workflow, non iniziare con una campagna. Inizia con qualcosa di piccolo che conta — un singolo post social, un mockup di prodotto, un semplice asset di brand — e passalo attraverso la Modalità Pensiero. Non prestare attenzione alla qualità dell'output (che probabilmente ti aspetti sia buona) ma a ciò che non hai dovutonon hai dovuto fare: nessun ritocco di prompt, nessuna conversione di formato, nessuna applicazione manuale del brand. Il valore di MCoT si misura nel lavoro che smetti di fare, non in quello che inizi a fare.
L'era della generazione IA ci ha dato macchine che potevano creare immagini. L'era agentica — ciò che MCoT rappresenta — ci dà macchine che possono partecipare al processo di design. Non sono la stessa cosa. E una volta che hai sperimentato la differenza, tornare alla generazione one-shot sembra come scambiare un collaboratore con un distributore automatico.