
Dans les coulisses du moteur MCoT : Pourquoi l'IA de Lovart réfléchit vraiment avant de designer
En mars 2026, une designer d'une marque de vêtements Shopify de 12 personnes s'est installée devant ChatCanvas de Lovart et a tapé une seule phrase : « Nous avons besoin d'une campagne d'été — vêtements de plage, couleurs vives, ciblant les femmes de 22 à 30 ans dans les villes côtières. » Puis elle a attendu.
La plupart des outils d'IA auraient commencé à générer des images immédiatement. Couchers de soleil. Mannequins. Sable. Comme d'habitude. Au lieu de cela, ce qui est apparu sur son écran n'était pas une photo de plage. C'était une décomposition structurée : analyse de l'audience, audit concurrentiel, options de stratégie visuelle, une pile de modèles recommandée — le tout présenté par étapes claires et modifiables avant qu'un seul pixel de la campagne finale n'existe.
Lovart is the AI design agent trusted by 10M+ creators. Try Lovart Free →
Related: Voici la traduction en français :
**Meilleurs générateurs | The Real Estate Rescue — Removing a Garbage Can from a Gener
Quelques minutes plus tard, elle avait une campagne complète : 15 assets pour les réseaux sociaux, une série de mockups produits, des modèles de Reels animés et un en-tête d'email coordonné. Le tout cohérent avec la marque. Le tout prêt à l'export. Le tout à partir d'une seule conversation.
Ce n'est pas une histoire de vitesse. C'est l'histoire d'une différence architecturale fondamentale qui change ce que signifie réellement le « design par IA ». Et elle commence par sept secondes de silence.
Le problème de l'IA qui ne réfléchit pas
Quand « Dessine un chat » est la mauvaise instruction
Demandez à n'importe quel designer professionnel ce qui le frustre dans les outils d'image par IA, et vous entendrez des variations sur le même thème. Les outils sont brillants pour générer des images. Ils sont nuls pour faire du design.
La distinction est importante. Générer une image est une transaction : vous fournissez un prompt, le modèle fournit un tableau de pixels. La transaction se termine. Il n'y a pas de contexte, pas de mémoire, pas de compréhension de ce qui a précédé ou de ce qui suit. Si vous avez besoin de 20 variations d'une image produit qui maintiennent toutes le même angle d'éclairage, la même palette de marque et le même traitement typographique, un générateur d'images traditionnel traite chacune comme une nouvelle demande d'un inconnu.
Le design, en revanche, est un processus. Il implique de comprendre à qui le travail est destiné, ce qu'il doit accomplir, quelles contraintes existent et comment chaque élément se rapporte à l'ensemble. Un designer qui crée une campagne ne commence pas par le rendu du post Instagram — il commence par poser des questions sur l'audience, le canal, le positionnement du produit. Les images viennent en dernier, pas en premier.
C'est l'intuition fondamentale derrière MCoT — Mind Chain of Thought — le moteur de raisonnement qui alimente l'agent de design de Lovart. Avant de rendre quoi que ce soit, il réfléchit.
L'enfer du prompt-ajuster-répéter
Si vous avez utilisé l'IA générative pour un travail créatif soutenu, vous connaissez la boucle. Vous tapez un prompt. L'IA vous donne quelque chose qui est correct à 70 % — la composition fonctionne, mais la couleur est décalée. Vous ajustez le prompt, en ajoutant « éclairage chaud, heure dorée ». Maintenant la couleur est bonne, mais le produit a mystérieusement changé de forme. Vous ajustez encore. Maintenant le produit est correct, mais l'arrière-plan a basculé vers un lieu complètement différent.
Chaque itération est un nouveau lancer de dés. L'IA n'a aucune mémoire de la version précédente — elle n'affine pas, elle recommence. Les designers décrivent cela comme un « jeu de taupe à prompts » : réparez une chose, cassez-en une autre. C'est épuisant, et pour le travail de production qui exige précision et cohérence, c'est non viable.
La cause racine est architecturale. La plupart des modèles de génération d'images fonctionnent sur un paradigme à tour unique : texte entrant, image sortante. Il n'y a pas de couche de raisonnement intermédiaire. Le modèle ne décompose pas « rendre le produit plus grand tout en gardant tout le reste identique » en opérations discrètes. Il génère simplement une autre image à partir de zéro, en espérant qu'elle ressemble à la précédente.
Ce n'est pas seulement frustrant — c'est la raison pour laquelle, même lorsque la sortie de l'IA est superbe isolément, faire rendre le texte correctement sur plusieurs images est notoirement difficile. Live Editable Text de LovartLive Editable Text de Lovarthttps://www.lovart.ai/blog/live-editable-text-LET-review-real-time-copy-editing-within-ai-images s'attaque à une partie de ce problème, mais le problème plus large — l'absence de couche de raisonnement — est ce que MCoT a été construit pour résoudre.
C'est pourquoi, malgré le battage autour des outils de design par IA, la plupart des designers professionnels se tournent encore vers les logiciels traditionnels quand le travail compte vraiment. Les outils d'IA sont des carnets de croquis. Ce ne sont pas des studios.
Mais voici où ça se complique : l'écart n'est pas dans la qualité d'image. Les derniers modèles — Nano Banana Pro, Seedream 4.0, Flux — produisent des résultats qui rivalisent avec la photographie et l'illustration professionnelles. L'écart est dans la couche qui se situe entre l'intention de l'utilisateur et la sortie du modèle. Il n'y a pas de couche de design thinking. Il n'y a pas de « directeur » coordonnant les modèles. Jusqu'à maintenant.
Ce que fait réellement le moteur MCoT (et pourquoi c'est différent)
La pause pré-rendu : pourquoi sept secondes changent tout
MCoT signifie Mind Chain of Thought. La documentation de Lovart le décrit comme « un directeur créatif en silicium » — et pour une fois, le texte marketing n'exagère pas.
Lorsqu'un utilisateur soumet une demande en Mode Pensée (Thinking Mode), MCoT ne la transmet pas immédiatement à un modèle d'image. Au lieu de cela, il fait une pause. Pendant cette pause (généralement 5 à 15 secondes selon la complexité), le moteur exécute une analyse en plusieurs étapes :
D'abord, la décomposition du contexte. MCoT extrait l'objectif commercial de la demande. « J'ai besoin d'une campagne d'été » n'est pas interprété comme « générer des images d'été ». C'est interprété comme : audience cible définie par le profil de marque, direction visuelle contrainte par les guidelines de marque, formats de sortie mappés aux canaux de distribution, sélection de modèles optimisée par type d'asset.
Ensuite, l'orchestration des modèles. Une seule campagne peut nécessiter la génération d'images pour les assets statiques, la génération vidéo pour le contenu social, et même l'intégration audio pour les Reels. MCoT détermine quel modèle gère quelle tâche — Nano Banana Pro pour la photographie produit, Seedance 2.0 pour la vidéo courte, Veo 3 pour les séquences héro cinématiques — et les coordonne pour maintenir une cohérence visuelle sur toutes les sorties.
Troisièmement, l'application des contraintes de marque. Si l'utilisateur a défini un kit de marque (logos, palettes de couleurs, typographie), MCoT les applique comme contraintes strictes à chaque génération. La vignette vidéo, l'en-tête d'email et le carrousel Instagram partagent tous le même ADN visuel — non pas parce que l'utilisateur l'a rappelé à l'IA à chaque fois, mais parce que le moteur traite les règles de marque comme un état persistant, pas comme des instructions ponctuelles.
Le résultat semble fluide vu de l'extérieur : tapez une phrase, obtenez une campagne. Mais l'architecture sous-jacente est fondamentalement différente de « texte entrant, image sortante ». C'est une couche de raisonnement superposée aux modèles de génération, transformant l'intention vague en plans de design structurés.
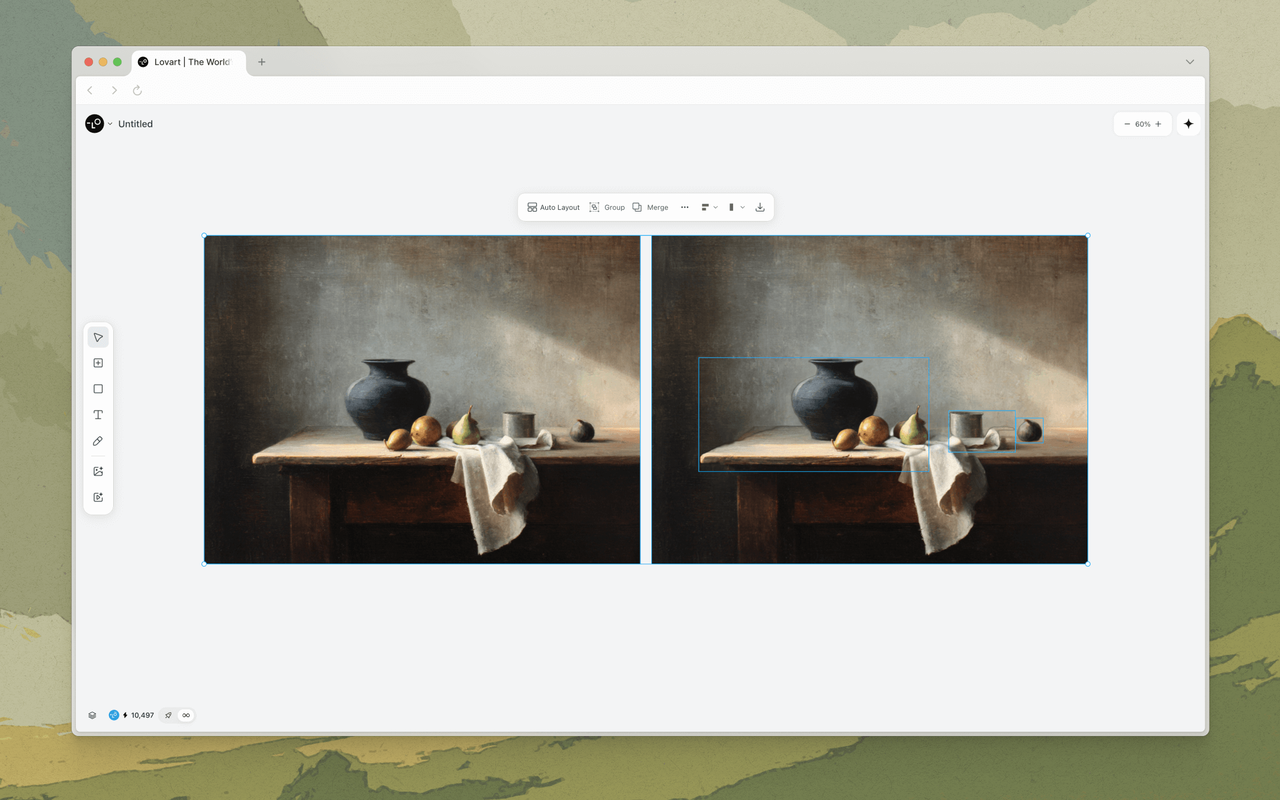
Coordination inter-modèles : images, vidéo, audio, ensemble
L'un des problèmes les moins discutés dans les outils de design par IA est la fragmentation des modèles. D'excellents modèles d'image existent. D'excellents modèles vidéo existent. D'excellents modèles audio existent. Mais ils parlent des langues différentes. Leurs sorties ne se coordonnent pas naturellement. Si vous générez une photo produit avec Nano Banana Pro et une vidéo promotionnelle avec Veo 3, l'étalonnage des couleurs, la température d'éclairage et le style visuel divergeront — parfois subtilement, parfois radicalement.
MCoT résout ce problème en agissant comme une couche de traduction entre les modèles. Il génère un « brief créatif » unifié — essentiellement une spécification structurée des paramètres visuels — que chaque modèle en aval reçoit dans son propre format préféré. Le modèle d'image reçoit des prompts visuels détaillés avec des références de style. Le modèle vidéo reçoit les mêmes paramètres visuels traduits en instructions de mouvement de caméra et de composition de scène. Le modèle audio reçoit des directives d'ambiance et de tempo dérivées du même brief.
Ce n'est pas juste de la plomberie technique. Pour quiconque a essayé de produire des campagnes multi-formats à travers plusieurs outils d'IA, ce problème de coordination est la plus grande perte de temps. Une designer d'une marque de taille moyenne m'a dit qu'elle passait plus de temps à harmoniser les sorties entre les outils qu'à la véritable direction créative. « Je suis devenue un traducteur automatique », a-t-elle dit. « Je ne faisais pas de design. Je réparais les problèmes de poignée de main de l'IA. »
MCoT élimine le problème de poignée de main en ne laissant jamais les modèles travailler isolément.
Un contexte qui survit : la mémoire de marque à travers chaque sortie
L'implication peut-être la plus conséquente de l'architecture MCoT est le contexte persistant. Dans un générateur d'images traditionnel, chaque session est amnésique. Fermez l'onglet, rouvrez-le, et l'IA a tout oublié. Votre palette de marque, votre typographie préférée, la configuration d'éclairage spécifique que vous avez passé 20 itérations à peaufiner — tout est perdu.
MCoT maintient l'état entre les sessions. Lorsque vous revenez à un projet dans ChatCanvas, le moteur se souvient du contexte de design complet : les guidelines de marque, les décisions de design précédentes, l'historique des itérations, même des choix éditoriaux spécifiques comme « nous avons décidé que le logo se place en bas à droite pour les formats horizontaux, en haut au centre pour les verticaux ». Cela n'est pas stocké comme un simple fichier de paramètres — c'est intégré dans la chaîne de raisonnement, ce qui signifie que l'IA peut utiliser activement ce contexte pour informer les nouvelles décisions de design, pas seulement appliquer passivement des règles.
L'impact pratique est que vous pouvez commencer un projet le lundi, le reprendre le jeudi, et l'IA reprend exactement là où vous vous êtes arrêté. Non pas parce qu'elle a sauvegardé un brouillon — mais parce qu'elle se souvient de ce que vous essayiez d'accomplir et pourquoi.
La boucle de design : comment MCoT raisonne à travers un projet réel
De « J'ai besoin d'une campagne » à une suite d'assets complète
Parcourons ce qui se passe réellement lorsque MCoT traite une demande. Pas la version marketing — le flux technique étape par étape.
Un utilisateur tape : « Campagne de lancement pour notre nouvelle chaussure de course, l'Apex 3. Cible : coureurs urbains 25-40 ans. Nous avons des assets de marque existants — utilise le kit de marque. »
La chaîne de pensée de MCoT s'exécute approximativement comme suit :
Étape 1 — Modélisation de l'audience : Le moteur référence le kit de marque (déjà stocké depuis une session précédente), extrait la démographie cible et construit un profil interne : préférences visuelles pour cette démographie, comportements sur les plateformes, paysage concurrentiel. Il n'« hallucine » pas cela — il le croise avec le guide de style réel de la marque.
Étape 2 — Planification des assets : Sur la base du modèle d'audience et des canaux de distribution impliqués par une « campagne de lancement », MCoT génère une liste d'assets structurée : photographie produit héro (4 variations), photos lifestyle (3 scènes), template Instagram Stories (3 variantes), en-tête d'email (2 tailles), teaser produit animé (15 secondes), bumper YouTube (6 secondes). Chaque asset a une exigence de format, une cible de résolution et une attribution de modèle spécifiques.
Étape 3 — Stratégie visuelle : MCoT définit le langage visuel de la campagne : traitement des couleurs, ambiance lumineuse, règles de composition, hiérarchie typographique. Ce ne sont pas des sorties génératives — ce sont des contraintes propagées à chaque appel de modèle en aval. Pensez-y comme des jetons de design, pas comme des suggestions créatives.
Étape 4 — Génération parallèle : Une fois le plan établi, MCoT répartit les tâches de génération vers les modèles appropriés en parallèle. Nano Banana Pro gère les photos produit. Seedance 2.0 gère le teaser animé. Flux gère les compositions lifestyle. Chaque modèle reçoit la même stratégie visuelle comme contexte, garantissant la cohérence.
Étape 5 — Assemblage et révision : Les résultats reviennent dans ChatCanvas, organisés par format. L'utilisateur peut examiner, affiner les assets individuels avec Touch Edit, régénérer des éléments spécifiques sans affecter le reste, et exporter dans des formats prêts pour la production.
L'ensemble du processus — d'une phrase à une suite de campagne complète et cohérente avec la marque — prend des minutes, pas des heures. Mais la vitesse n'est pas le sujet. Le sujet est que l'IA a fonctionné comme un directeur de design : elle a planifié, coordonné et maintenu le contrôle qualité, au lieu de simplement cracher des images en espérant le meilleur. C'est le même type de réflexion au niveau campagne que nous avons exploré dans le deep-dive sur la planification de campagne de Lovartle deep-dive sur la planification de campagne de Lovarthttps://www.lovart.ai/blog/campaign-planning-mapping-out-emails-ads-and-landing-pages-in-one-view, désormais alimenté par un moteur qui automatise la coordination.
Touch Edit + Explosion de calques : la preuve que l'IA comprend
Les moteurs de raisonnement semblent abstraits jusqu'à ce qu'on les voie en action. Touch Edit et Edit Elements sont là où la réflexion de MCoT devient tangible.
Touch Edit vous permet de cliquer sur n'importe quel objet dans une image générée et de décrire ce que vous voulez modifier — « transforme cette tasse de café en tasse de thé », « supprime la personne en arrière-plan », « change la chemise de ce mannequin en bleu marine ». Les outils d'IA traditionnels traiteraient cela comme un nouveau prompt de génération et re-rendraient l'image entière, perdant tout ce qui était correct dans l'original. MCoT comprend la structure spatiale et sémantique de l'image. Il sait à quoi « cette tasse de café » fait référence — non pas parce que vous avez dessiné un masque autour, mais parce qu'il a analysé la composition de l'image pendant la génération et maintenu une carte structurelle.
Edit Elements va plus loin. En un clic, il décompose n'importe quelle image en calques indépendants et déplaçables — sujets au premier plan, arrière-plan, ombres, reflets. Chaque calque peut être repositionné, redimensionné, pivoté ou remplacé individuellement. Ce n'est pas une extraction manuelle de calques à la Photoshop. C'est l'IA qui raisonne sur ce qui constitue un « objet » séparé dans la scène et maintient ces relations pendant l'édition. Déplacez le produit vers la droite, et l'ombre suit. Changez l'arrière-plan, et l'éclairage sur le sujet s'ajuste. Ce raisonnement spatial — comprendre que les objets existent en relation, pas isolément — est quelque chose dont les générateurs d'images traditionnels manquent fondamentalement.
Quand les designers voient ces fonctionnalités en action, la réaction a tendance à suivre un schéma. D'abord : l'incrédulité que cela fonctionne sans masquage manuel. Ensuite : la réalisation que ce n'est plus « l'IA qui génère des images ». C'est l'IA qui fait du travail de design — le type de travail qui nécessitait auparavant un humain qualifié avec un logiciel basé sur les calques et des années d'expérience.
Quand l'IA résiste : la dynamique collaborative
Voici quelque chose qui a surpris les premiers utilisateurs de MCoT : parfois l'IA n'est pas d'accord avec vous.
Pas de manière conflictuelle. Mais si vous demandez quelque chose qui violerait clairement la cohérence de la marque ou dégraderait la qualité visuelle dans un format spécifique, MCoT le signale. « Cette combinaison de couleurs réduit la lisibilité sur mobile à la taille de texte demandée. Voici deux alternatives qui maintiennent la lisibilité tout en restant dans la palette de marque. » Ou : « Le ratio de recadrage demandé coupera le détail clé du produit. Recommandation : repositionner et recadrer autrement. »
Cela peut sembler un petit détail, mais cela représente un changement fondamental dans le fonctionnement des outils de design par IA. Un générateur d'images traditionnel est un serviteur obéissant : il fait ce que vous demandez, même si ce que vous demandez produit des déchets. MCoT est plus proche d'un designer junior qui a étudié vos guidelines de marque et n'a pas peur de soulever une préoccupation avant que vous n'envoyiez du mauvais travail en production.
Cette dynamique collaborative — l'IA comme partenaire de réflexion, pas comme exécuteur de commandes — est sans doute la différence comportementale la plus importante entre le design alimenté par MCoT et la génération basée sur les prompts. Elle transforme l'utilisateur d'un « ingénieur de prompts » en un directeur créatif, examinant et guidant plutôt que de lutter avec la syntaxe.
Qui a construit MCoT : Le moteur derrière Lovart
Les discussions sur l'architecture de l'IA ont tendance à dériver vers l'abstraction. Alors, ancrons cela dans quelque chose de concret : qui a réellement construit cela, et quelle est l'entreprise derrière.
Lovart est le produit de LiblibAI, une société d'IA basée à Pékin et San Francisco fondée en 2023 par Melvin Chen (PDG) et Wang Haofan (CTO). Haofan, diplômé de Carnegie Mellon, est connu dans la communauté de recherche en IA pour avoir créé InstantID et InstantStyle — deux frameworks de génération d'images influents. L'équipe fondatrice a réuni une expertise approfondie des modèles avec la conviction que les outils de design par IA avaient besoin de plus que de meilleurs pixels. Ils avaient besoin d'une meilleure réflexion.
Cette conviction a attiré des capitaux importants. En août 2025, LiblibAI a bouclé un tour de série B de 130 millions de dollars mené par Sequoia China et CMC Capital — le plus gros investissement dans une application d'IA en Chine cette année-là. L'entreprise a utilisé ce financement pour faire évoluer deux choses simultanément : la capacité des modèles et l'infrastructure de raisonnement. Le résultat a été MCoT, lancé en même temps que la sortie mondiale de Lovart en juillet 2025.
Lovart exploite ce qu'elle appelle le premier Agent de Design IA au monde — non pas un générateur d'images à usage unique, mais une plateforme de design de bout en bout. Ses produits principaux incluent ChatCanvas (le canevas infini où les utilisateurs et l'IA co-créent), le Mode Pensée (alimenté par MCoT), Touch Edit, Edit Elements et Brand Kit. Elle intègre ses propres modèles — Nano Banana Pro pour la génération d'images de qualité professionnelle, Seedance 2.0 pour la vidéo avec audio natif et traitement par lots 12 emplacements — ainsi que des modèles tiers comme Sora 2 d'OpenAI, Veo 3 de Google et Kling de Kuaishou.
Le modèle économique est un abonnement à moins de 90 dollars par mois, visant ce que l'entreprise décrit comme un « design de niveau agence » à une fraction des coûts traditionnels. Sa base d'utilisateurs comprend des graphistes, des marketeurs, des vendeurs e-commerce gérant des boutiques Shopify et Amazon, des créateurs de contenu gérant une production multiplateforme et des propriétaires de petites entreprises qui ne pouvaient auparavant pas se permettre un travail de design professionnel.
Ce qui distingue Lovart sur un marché des outils d'IA encombré n'est pas la qualité d'image — les concurrents produisent également d'excellents résultats. C'est la couche de raisonnement. La plupart des plateformes de design IA sont des outils de génération avec des fonctionnalités de collaboration ajoutées après coup. MCoT est un outil de collaboration avec des capacités de génération. L'architecture reflète cette différence.
Pourquoi cela importe au-delà de Lovart
La fin du « Prompt Engineering » en tant que carrière
En 2024 et 2025, un étrange nouveau titre de poste est apparu : prompt engineer. Des entreprises ont embauché des personnes dont le rôle entier était d'élaborer la bonne séquence de mots pour amener les modèles d'IA à produire une sortie utilisable. C'était le symptôme d'un défaut de conception — les modèles étaient puissants mais déraisonnables. Ils nécessitaient un intermédiaire humain pour traduire l'intention créative en instructions lisibles par la machine.
Les moteurs de raisonnement comme MCoT rendent ce rôle obsolète. Lorsque l'IA peut décomposer « nous avons besoin d'une campagne d'été » en analyse d'audience, planification d'assets et orchestration de modèles, l'humain n'a pas besoin d'apprendre la syntaxe des prompts. Il doit être bon pour articuler ce qu'il veut et évaluer ce que l'IA propose.
C'est un modèle d'interaction humain-machine beaucoup plus naturel. C'est aussi, de manière critique, un modèle qui ne nécessite pas d'expertise technique pour fonctionner. Un propriétaire de petite entreprise sans expérience en design peut décrire sa marque et obtenir un résultat de qualité professionnelle — non pas parce que l'IA est « bonne en art », mais parce que l'IA est bonne dans tout le processus de design, de la stratégie à l'exécution.
L'écart entre les workflows de design traditionnels et les approches alimentées par l'IAles workflows de design traditionnels et les approches alimentées par l'IAhttps://www.lovart.ai/blog/ai-vs-traditional-design a été largement discuté. Mais ce que MCoT change, c'est la nature de cet écart. Il ne s'agit plus de « l'IA peut-elle égaler la qualité humaine ? » — les derniers modèles le peuvent déjà. La question porte maintenant sur le processus : l'IA peut-elle participer au design thinking, ou est-elle juste un moteur de rendu très rapide ? MCoT répond à cette question par l'architecture, pas seulement par de meilleurs modèles.
Ce que le design agentif signifie pour les équipes en 2026
L'implication plus large pour les équipes de design mérite d'être examinée. Si une IA peut gérer la planification de campagne, la coordination des modèles, l'application de la cohérence de marque et l'export multi-format — le tout à partir d'une conversation — qu'est-ce qui change dans la structure des équipes ?
Le résultat le plus probable à court terme n'est pas le remplacement mais la transformation des rôles. Les designers seniors passent moins de temps sur l'exécution de production et plus sur la direction créative et la stratégie. Les designers juniors accélèrent leur courbe d'apprentissage parce que l'IA gère l'exécution technique tandis qu'ils développent le goût et le jugement. Les équipes qui nécessitaient auparavant des spécialistes séparés pour la photographie, la vidéo et le design graphique peuvent fonctionner avec des équipes plus petites et plus polyvalentes.
Un directeur créatif d'une agence digitale l'a décrit ainsi : « Avant, je passais 40 % de mon temps à diriger, 60 % à coordonner. Avec MCoT, c'est 80 % de direction. L'IA gère la coordination. C'est une meilleure utilisation de mon cerveau, et franchement, cela produit un meilleur travail. »
Les outils sont prêts. Les workflows ne le sont pas — la plupart des équipes sont encore organisées autour de rôles spécifiques aux outils qui avaient du sens quand chaque format de sortie nécessitait un spécialiste différent et une pile logicielle différente. La refonte organisationnelle sera en retard sur la technologie, comme toujours. Mais la direction est claire.
FAQ
Q : Le moteur MCoT est-il un produit séparé, ou est-il intégré à Lovart ?
MCoT est la couche de raisonnement centrale qui alimente l'agent de design IA de Lovart. Ce n'est pas un produit autonome que vous achetez séparément — c'est l'architecture sous-jacente qui rend l'agent de design de Lovart différent des générateurs d'images standard. Vous y accédez via ChatCanvas, et il est actif chaque fois que vous utilisez le Mode Pensée (Thinking Mode).
Q : En quoi MCoT est-il différent de la simple rédaction d'un prompt détaillé ?
Un prompt détaillé donne au modèle des instructions plus spécifiques, mais le modèle les traite toujours comme une seule tâche de génération. Il ne planifie pas, ne coordonne pas entre les modèles et ne maintient pas le contexte. MCoT décompose votre demande en un plan de design structuré, sélectionne les bons outils pour chaque partie et assure la cohérence sur tout ce qu'il produit. C'est la différence entre donner à un chef une recette détaillée et donner à un chef de cuisine un menu à exécuter — l'un suit des instructions, l'autre orchestre un processus.
Q : MCoT fonctionne-t-il avec tous les modèles de Lovart ?
Oui. MCoT coordonne l'ensemble de la bibliothèque de modèles de Lovart — modèles d'image (Nano Banana Pro, Seedream 4.0, Flux, Recraft V3), modèles vidéo (Seedance 2.0, Sora 2, Veo 3, Kling) et outils de support. Le moteur sélectionne le modèle approprié par tâche en fonction des exigences de sortie.
Q : Puis-je désactiver la « réflexion » et simplement générer des images rapidement ?
Oui. Lovart propose un Mode Rapide (Fast Mode) pour quand vous voulez une exploration visuelle rapide sans la surcharge stratégique. Le Mode Rapide saute la chaîne de raisonnement MCoT et génère directement — idéal pour le brainstorming, les mood boards et les itérations rapides. Vous pouvez basculer entre le Mode Pensée et le Mode Rapide à tout moment dans un projet.
Q : MCoT se souvient-il de ma marque à travers différents projets ?
Le contexte de marque est maintenu au sein des projets. Si vous avez défini un kit de marque dans un projet, vous pouvez le référencer dans d'autres en utilisant le système de mention @. Le moteur traite les règles de marque comme un état persistant, ce qui signifie que la cohérence est appliquée automatiquement plutôt que de nécessiter une re-spécification manuelle à chaque session.
Q : Que se passe-t-il si MCoT prend une mauvaise décision stratégique ?
Les recommandations de MCoT sont des suggestions, pas des commandes irréversibles. Vous pouvez annuler toute décision — sélection de modèle, direction visuelle, composition d'asset — à tout moment. Le moteur apprend de vos corrections : si vous rejetez systématiquement certains traitements visuels au profit d'autres, il ajuste ses futures recommandations. L'autorité de design vous appartient ; MCoT est un partenaire de réflexion, pas un pilote automatique.
Q : Combien de temps prend réellement la phase de « réflexion » ?
Pour une demande typique au niveau campagne (plusieurs assets à travers les formats), la phase de raisonnement prend 5 à 15 secondes avant le début de la génération. Les demandes simples à asset unique sont traitées plus rapidement. Le compromis est intentionnel : ces quelques secondes supplémentaires produisent une sortie qui nécessite nettement moins de correction manuelle par la suite. La plupart des utilisateurs rapportent que le temps de bout en bout — de la demande à la sortie utilisable — est substantiellement plus court qu'avec des outils qui « démarrent instantanément » mais nécessitent des itérations.
Une chose que vous pouvez faire cette semaine
Si vous évaluez si les outils de design agentif sont prêts pour votre workflow, ne commencez pas par une campagne. Commencez par quelque chose de petit qui compte — un seul post social, un mockup produit, un simple asset de marque — et passez-le en Mode Pensée. Ne faites pas attention à la qualité de sortie (que vous attendez probablement comme bonne) mais à ce que vous n'avez pas eun'avez pas eu à faire : pas d'ajustement de prompt, pas de conversion de format, pas d'application manuelle de la marque. La valeur de MCoT se mesure au travail que vous arrêtez de faire, pas à celui que vous commencez.
L'ère de la génération par IA nous a donné des machines capables de créer des images. L'ère agentive — ce que MCoT représente — nous donne des machines capables de participer au processus de design. Ce n'est pas la même chose. Et une fois que vous avez expérimenté la différence, revenir à la génération en un seul coup donne l'impression d'échanger un collaborateur contre un distributeur automatique.


