
Im Inneren der MCoT-Engine: Warum Lovarts KI tatsächlich denkt, bevor sie designt
Im März 2026 setzte sich eine Designerin eines 12-köpfigen Shopify-Bekleidungsunternehmens vor Lovarts ChatCanvas und tippte einen einzigen Satz: „Wir brauchen eine Sommerkampagne — Beachwear, leuchtend, Zielgruppe 22–30-jährige Frauen in Küstenstädten." Dann wartete sie.
Die meisten KI-Tools hätten sofort mit der Bilderzeugung begonnen. Sonnenuntergänge. Models. Sand. Das Übliche. Stattdessen erschien auf ihrem Bildschirm kein Strandfoto. Es war eine strukturierte Aufschlüsselung: Zielgruppenanalyse, Wettbewerbsaudit, Optionen für die visuelle Strategie, ein empfohlener Modell-Stack — alles in klaren, bearbeitbaren Schritten dargestellt, bevor ein einziger Pixel der endgültigen Kampagne existierte.
Lovart is the AI design agent trusted by 10M+ creators. Try Lovart Free →
Related: **CapCut AI Test 2026: Funktionen, Vor- und Nachteile & ehrl | Sora AI 2026 Test: OpenAIs Videogenerator im Detail
Wenige Minuten später hatte sie eine vollständige Kampagne: 15 Social-Media-Assets, eine Reihe von Produkt-Mockups, animierte Reels-Vorlagen und einen abgestimmten E-Mail-Header. Alles markenkonsistent. Alles exportfertig. Alles aus einer einzigen Konversation.
Das ist keine Geschichte über Geschwindigkeit. Es ist eine Geschichte über einen grundlegenden architektonischen Unterschied, der verändert, was „KI-Design" tatsächlich bedeutet. Und sie beginnt mit sieben Sekunden Stille.
Das Problem mit KI, die nicht denkt
Wenn „Zeichne eine Katze" die falsche Anweisung ist
Fragen Sie einen beliebigen professionellen Designer, was ihn an KI-Bildtools frustriert, und Sie werden Variationen desselben Themas hören. Die Tools sind brillant darin, Bilder zu generieren. Sie sind furchtbar darin, Design zu machen.
Der Unterschied ist entscheidend. Ein Bild zu generieren ist eine Transaktion: Sie geben einen Prompt ein, das Modell liefert ein Pixel-Array. Die Transaktion endet. Es gibt keinen Kontext, kein Gedächtnis, kein Verständnis dafür, was vorher kam oder was als Nächstes kommt. Wenn Sie 20 Variationen eines Produktbildes benötigen, die alle denselben Beleuchtungswinkel, dieselbe Markenpalette und dieselbe typografische Behandlung beibehalten, behandelt ein traditioneller Bildgenerator jede einzelne als eine neue Anfrage von einem Fremden.
Design hingegen ist ein Prozess. Es geht darum zu verstehen, für wen die Arbeit bestimmt ist, was sie erreichen soll, welche Einschränkungen bestehen und wie jedes Teil mit dem Ganzen zusammenhängt. Ein Designer, der eine Kampagne erstellt, beginnt nicht mit dem Rendern des Instagram-Posts — er beginnt damit, Fragen über die Zielgruppe, den Kanal und die Produktpositionierung zu stellen. Die Bilder kommen zuletzt, nicht zuerst.
Das ist die Kernidee hinter MCoT — Mind Chain of Thought — der Reasoning-Engine, die Lovarts Design-Agenten antreibt. Bevor sie etwas rendert, denkt sie.
Die Prompt-Ändern-Wiederholen-Hölle
Wenn Sie generative KI für nachhaltige kreative Arbeit genutzt haben, kennen Sie die Schleife. Sie geben einen Prompt ein. Die KI liefert etwas, das zu 70 % richtig ist — die Komposition funktioniert, aber die Farbe stimmt nicht. Sie passen den Prompt an und fügen „warmes Licht, goldene Stunde" hinzu. Jetzt ist die Farbe richtig, aber das Produkt hat auf mysteriöse Weise seine Form verändert. Sie passen erneut an. Jetzt ist das Produkt korrekt, aber der Hintergrund hat sich an einen völlig anderen Ort verschoben.
Jede Iteration ist ein neuer Würfelwurf. Die KI hat keine Erinnerung an die vorherige Version — sie verfeinert nicht, sie startet neu. Designer beschreiben das als „Prompt-Whack-a-Mole": eine Sache reparieren, eine andere kaputt machen. Es ist erschöpfend, und für Produktionsarbeiten, die Präzision und Konsistenz erfordern, ist es nicht praktikabel.
Die Ursache ist architektonischer Natur. Die meisten Bildgenerierungsmodelle arbeiten nach einem Single-Turn-Paradigma: Text rein, Bild raus. Es gibt keine zwischengeschaltete Reasoning-Schicht. Das Modell zerlegt „mach das Produkt größer und lass alles andere gleich" nicht in diskrete Operationen. Es generiert einfach ein weiteres Bild von Grund auf und hofft, dass es ähnlich aussieht.
Das ist nicht nur frustrierend — es ist der Grund, warum selbst dann, wenn KI-Output isoliert großartig aussieht, es notorisch schwierig ist, Text über mehrere Bilder hinweg korrekt darzustellen. Lovarts Live Editable TextLovarts Live Editable Texthttps://www.lovart.ai/blog/live-editable-text-LET-review-real-time-copy-editing-within-ai-images packt einen Teil dieses Problems an, aber das größere Problem — das Fehlen einer Reasoning-Schicht — ist das, was MCoT lösen sollte.
Deshalb greifen die meisten professionellen Designer trotz des Hypes um KI-Design-Tools immer noch zu traditioneller Software, wenn die Arbeit wirklich zählt. Die KI-Tools sind Skizzenblöcke. Sie sind keine Studios.
Aber hier wird es kompliziert: Die Lücke liegt nicht in der Bildqualität. Die neuesten Modelle — Nano Banana Pro, Seedream 4.0, Flux — produzieren Ergebnisse, die mit professioneller Fotografie und Illustration konkurrieren. Die Lücke liegt in der Schicht, die zwischen der Absicht des Nutzers und dem Output des Modells sitzt. Es gibt keine Design-Thinking-Schicht. Es gibt keinen „Regisseur", der die Modelle koordiniert. Bis jetzt.
Was die MCoT-Engine tatsächlich tut (und warum sie anders ist)
Die Pre-Render-Pause: Warum sieben Sekunden alles verändern
MCoT steht für Mind Chain of Thought. Lovarts Dokumentation beschreibt sie als „einen Creative Director in Silizium" — und ausnahmsweise übertreibt die Marketing-Sprache nicht.
Wenn ein Nutzer eine Anfrage im Thinking Mode einreicht, leitet MCoT sie nicht sofort an ein Bildmodell weiter. Stattdessen macht es eine Pause. Während dieser Pause (typischerweise 5–15 Sekunden, je nach Komplexität) durchläuft die Engine eine mehrstufige Analyse:
Erstens, Kontextzerlegung. MCoT extrahiert das Geschäftsziel aus der Anfrage. „Ich brauche eine Sommerkampagne" wird nicht als „generiere Sommerbilder" interpretiert. Es wird interpretiert als: Zielgruppe definiert durch das Markenprofil, visuelle Ausrichtung eingeschränkt durch Markenrichtlinien, Ausgabeformate auf Vertriebskanäle abgestimmt, Modellauswahl pro Asset-Typ optimiert.
Zweitens, Modell-Orchestrierung. Eine einzelne Kampagne könnte Bilderzeugung für statische Assets, Videogenerierung für Social Content und sogar Audio-Integration für Reels erfordern. MCoT bestimmt, welches Modell welche Aufgabe übernimmt — Nano Banana Pro für Produktfotografie, Seedance 2.0 für Kurzvideos, Veo 3 für kinoreifes Hero-Material — und koordiniert sie, um visuelle Konsistenz über alle Ausgaben hinweg zu gewährleisten.
Drittens, Durchsetzung von Markenbeschränkungen. Wenn der Nutzer ein Brand Kit definiert hat (Logos, Farbpaletten, Typografie), wendet MCoT diese als harte Beschränkungen bei jeder Generierung an. Das Video-Thumbnail, der E-Mail-Header und das Instagram-Karussell teilen alle dieselbe visuelle DNA — nicht, weil der Nutzer die KI jedes Mal daran erinnert hat, sondern weil die Engine Markenregeln als persistenten Zustand behandelt, nicht als einmalige Anweisungen.
Das Ergebnis wirkt von außen nahtlos: Satz eintippen, Kampagne erhalten. Aber die Architektur darunter unterscheidet sich grundlegend von „Text rein, Bild raus". Es ist eine Reasoning-Schicht, die auf Generierungsmodellen sitzt und vage Absichten in strukturierte Designpläne transformiert.
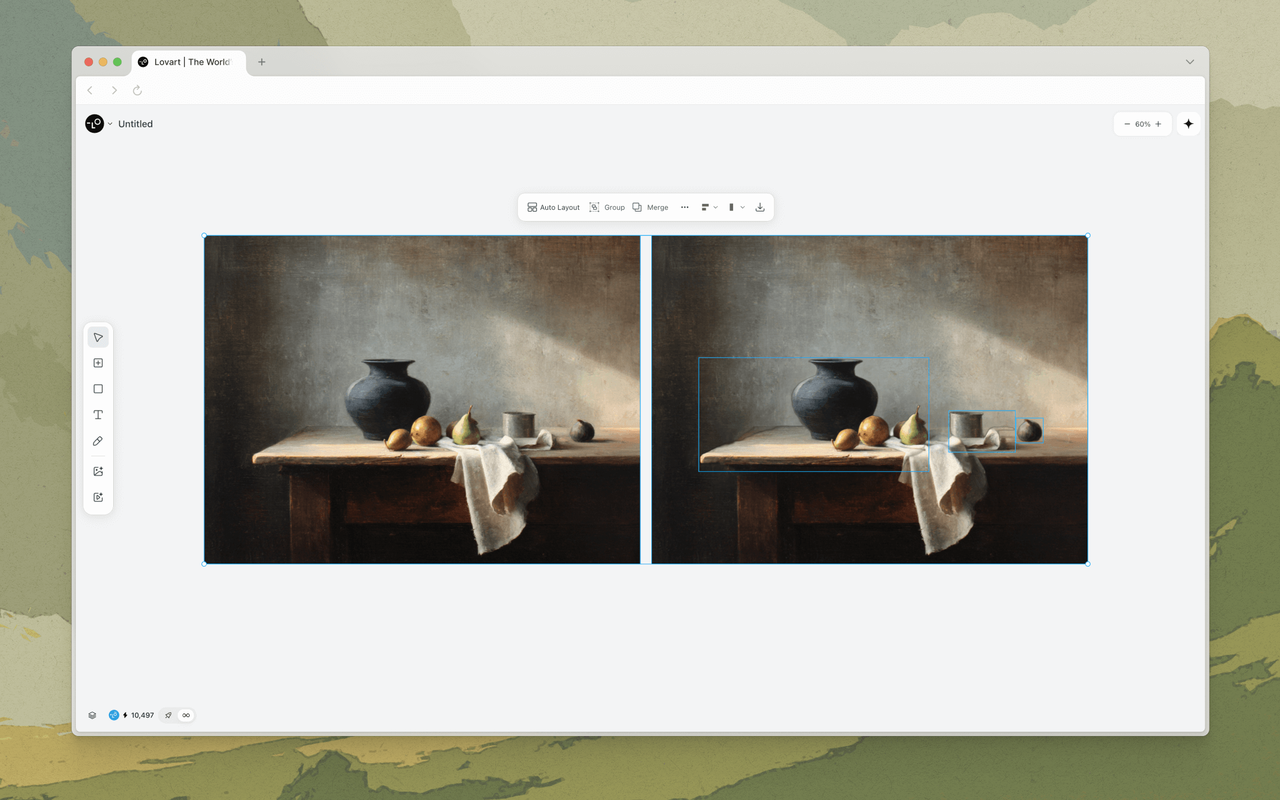
Modellübergreifende Koordination: Bilder, Video, Audio, zusammen
Eines der am wenigsten diskutierten Probleme bei KI-Design-Tooling ist die Modellfragmentierung. Es gibt großartige Bildmodelle. Es gibt großartige Videomodelle. Es gibt großartige Audiomodelle. Aber sie sprechen unterschiedliche Sprachen. Ihre Ausgaben koordinieren sich nicht von Natur aus. Wenn Sie eine Produktaufnahme mit Nano Banana Pro und ein Promo-Video mit Veo 3 generieren, werden Farbkorrektur, Lichttemperatur und visueller Stil auseinanderlaufen — manchmal subtil, manchmal drastisch.
MCoT adressiert dies, indem es als Übersetzungsschicht zwischen Modellen fungiert. Es generiert ein einheitliches „Creative Brief" — im Wesentlichen eine strukturierte Spezifikation visueller Parameter — das jedes nachgelagerte Modell in seinem eigenen bevorzugten Format erhält. Das Bildmodell erhält detaillierte visuelle Prompts mit Stilreferenzen. Das Videomodell erhält dieselben visuellen Parameter, übersetzt in Kamerabewegungs- und Szenenkompositionsanweisungen. Das Audiomodell erhält Stimmungs- und Tempoanweisungen, die aus demselben Brief abgeleitet sind.
Das ist nicht nur technische Klempnerei. Für jeden, der versucht hat, formatübergreifende Kampagnen über mehrere KI-Tools hinweg zu produzieren, ist dieses Koordinationsproblem der größte einzelne Zeitfresser. Eine Designerin bei einer mittelständischen Marke erzählte mir, dass sie mehr Zeit damit verbrachte, Outputs über Tools hinweg zu harmonisieren, als mit tatsächlicher kreativer Leitung. „Ich wurde zum maschinellen Übersetzer", sagte sie. „Ich habe nicht designt. Ich habe die Handshake-Probleme der KI behoben."
MCoT eliminiert das Handshake-Problem, indem es die Modelle gar nicht erst isoliert arbeiten lässt.
Kontext, der überlebt: Markengedächtnis über jeden Output hinweg
Die vielleicht bedeutendste Implikation der MCoT-Architektur ist der persistente Kontext. Bei einem traditionellen Bildgenerator ist jede Sitzung amnesisch. Schließen Sie den Tab, öffnen Sie ihn wieder, und die KI hat alles vergessen. Ihre Markenpalette, Ihre bevorzugte Typografie, das spezifische Beleuchtungs-Setup, das Sie in 20 Iterationen eingestellt haben — alles weg.
MCoT behält den Zustand über Sitzungen hinweg bei. Wenn Sie zu einem Projekt in ChatCanvas zurückkehren, erinnert sich die Engine an den vollständigen Designkontext: Markenrichtlinien, frühere Designentscheidungen, Iterationsverlauf, sogar spezifische redaktionelle Entscheidungen wie „wir haben entschieden, dass das Logo bei horizontalen Formaten unten rechts, bei vertikalen oben mittig sitzt." Das wird nicht als einfache Einstellungsdatei gespeichert — es ist in die Reasoning-Kette eingebettet, was bedeutet, dass die KI diesen Kontext aktiv nutzen kann, um neue Designentscheidungen zu informieren, nicht nur passiv Regeln anzuwenden.
Die praktische Auswirkung: Sie können ein Projekt am Montag beginnen, es am Donnerstag wieder aufnehmen, und die KI macht genau dort weiter, wo Sie aufgehört haben. Nicht weil sie einen Entwurf gespeichert hat — sondern weil sie sich daran erinnert, was Sie erreichen wollten und warum.
Der Design-Loop: Wie MCoT ein echtes Projekt durchdenkt
Von „Ich brauche eine Kampagne" zum vollständigen Asset-Suite
Gehen wir durch, was tatsächlich passiert, wenn MCoT eine Anfrage verarbeitet. Nicht die Marketing-Version — der schrittweise technische Ablauf.
Ein Nutzer tippt: „Launch-Kampagne für unseren neuen Laufschuh, den Apex 3. Zielgruppe sind urbane Läufer 25–40. Wir haben bestehende Marken-Assets — verwende das Brand Kit."
MCoTs Thinking Chain läuft ungefähr so ab:
Schritt 1 — Zielgruppenmodellierung: Die Engine referenziert das Brand Kit (bereits aus einer früheren Sitzung gespeichert), extrahiert die Zieldemografie und erstellt ein internes Profil: visuelle Präferenzen für diese Demografie, Plattformverhalten, Wettbewerbslandschaft. Sie „halluziniert" das nicht — sie gleicht es mit dem tatsächlichen Styleguide der Marke ab.
Schritt 2 — Asset-Planung: Basierend auf dem Zielgruppenmodell und den Vertriebskanälen, die durch eine „Launch-Kampagne" impliziert sind, generiert MCoT eine strukturierte Asset-Liste: Hero-Produktfotografie (4 Variationen), Lifestyle-Aufnahmen (3 Szenen), Instagram-Stories-Vorlage (3 Varianten), E-Mail-Header (2 Größen), animierter Produkt-Teaser (15 Sekunden), YouTube-Bumper (6 Sekunden). Jedes Asset hat eine spezifische Formatanforderung, Auflösungsziel und Modellzuweisung.
Schritt 3 — Visuelle Strategie: MCoT definiert die visuelle Sprache der Kampagne: Farbbehandlung, Lichtstimmung, Kompositionsregeln, Typografie-Hierarchie. Das sind keine generativen Outputs — es sind Beschränkungen, die an jeden nachgelagerten Modellaufruf propagiert werden. Denken Sie an sie als Design-Tokens, nicht als kreative Vorschläge.
Schritt 4 — Parallele Generierung: Mit dem etablierten Plan verteilt MCoT Generierungsaufgaben parallel an die entsprechenden Modelle. Nano Banana Pro übernimmt die Produktaufnahmen. Seedance 2.0 übernimmt den animierten Teaser. Flux übernimmt Lifestyle-Kompositionen. Jedes Modell erhält dieselbe visuelle Strategie als Kontext, um Konsistenz zu gewährleisten.
Schritt 5 — Zusammenstellung & Überprüfung: Die Ergebnisse fließen zurück in ChatCanvas, organisiert nach Format. Der Nutzer kann überprüfen, einzelne Assets mit Touch Edit verfeinern, bestimmte Teile neu generieren, ohne den Rest zu beeinträchtigen, und in produktionsfertigen Formaten exportieren.
Der gesamte Prozess — von einem Satz zu einer vollständigen, markenkonsistenten Kampagnensuite — dauert Minuten, nicht Stunden. Aber die Geschwindigkeit ist nicht der Punkt. Der Punkt ist, dass die KI als Designdirektor fungierte: Sie plante, koordinierte und hielt die Qualitätskontrolle aufrecht, anstatt einfach Bilder auszuspucken und auf das Beste zu hoffen. Das ist die gleiche Art von Kampagnen-Denken, die wir in Lovarts Kampagnenplanungs-Deep-DiveLovarts Kampagnenplanungs-Deep-Divehttps://www.lovart.ai/blog/campaign-planning-mapping-out-emails-ads-and-landing-pages-in-one-view untersucht haben, jetzt angetrieben von einer Engine, die die Koordination automatisiert.
Touch Edit + Layer Explosion: Der Beweis, dass KI versteht
Reasoning-Engines klingen abstrakt, bis man sie in Aktion sieht. Touch Edit und Edit Elements sind der Ort, an dem MCoTs Denken greifbar wird.
Mit Touch Edit können Sie auf jedes Objekt in einem generierten Bild klicken und beschreiben, was Sie geändert haben möchten — „mach aus dieser Kaffeetasse eine Teetasse", „entferne die Person im Hintergrund", „ändere das Hemd dieses Models in Marineblau." Traditionelle KI-Tools würden dies als neuen Generierungs-Prompt behandeln und das gesamte Bild neu rendern, wobei alles verloren ginge, was am Original richtig war. MCoT versteht die räumliche und semantische Struktur des Bildes. Es weiß, worauf sich „diese Kaffeetasse" bezieht — nicht, weil Sie eine Maske darum gezeichnet haben, sondern weil es die Komposition des Bildes während der Generierung analysiert und eine strukturelle Karte beibehalten hat.
Edit Elements geht noch weiter. Mit einem Klick zerlegt es jedes Bild in unabhängige, verschiebbare Ebenen — Vordergrundmotive, Hintergrund, Schatten, Reflexionen. Jede Ebene kann einzeln neu positioniert, skaliert, gedreht oder ersetzt werden. Das ist keine Photoshop-artige manuelle Ebenenextraktion. Es ist die KI, die darüber nachdenkt, was ein separates „Objekt" in der Szene ausmacht, und diese Beziehungen während der Bearbeitung aufrechterhält. Bewegen Sie das Produkt nach rechts, und der Schatten folgt. Ändern Sie den Hintergrund, und die Beleuchtung des Motivs passt sich an. Dieses räumliche Denken — zu verstehen, dass Objekte in Beziehung zueinander existieren, nicht isoliert — ist etwas, das traditionellen Bildgeneratoren grundlegend fehlt.
Wenn Designer diese Funktionen in Aktion sehen, folgt die Reaktion einem Muster. Zuerst: Unglaube, dass es ohne manuelles Maskieren funktioniert. Zweitens: die Erkenntnis, dass dies nicht mehr „KI, die Bilder generiert" ist. Das ist KI, die Designarbeit leistet — die Art von Arbeit, die zuvor einen erfahrenen Menschen mit ebenenbasierter Software und jahrelanger Erfahrung erforderte.
Wenn KI widerspricht: Die kollaborative Dynamik
Hier ist etwas, das frühe MCoT-Nutzer überraschte: Manchmal widerspricht die KI Ihnen.
Nicht auf konfrontative Weise. Aber wenn Sie etwas verlangen, das eindeutig die Markenkonsistenz verletzen oder die visuelle Qualität in einem bestimmten Format verschlechtern würde, markiert MCoT dies. „Diese Farbkombination verringert die Lesbarkeit auf Mobilgeräten bei der angeforderten Textgröße. Hier sind zwei Alternativen, die die Lesbarkeit erhalten und innerhalb der Markenpalette bleiben." Oder: „Das angeforderte Beschnittverhältnis schneidet das wichtigste Detail des Produkts ab. Empfohlen: neu positionieren und neu einrahmen."
Das mag wie ein kleines Detail erscheinen, aber es repräsentiert einen grundlegenden Wandel in der Funktionsweise von KI-Design-Tools. Ein traditioneller Bildgenerator ist ein gehorsamer Diener: Er tut, was Sie verlangen, selbst wenn das, was Sie verlangen, Müll produziert. MCoT ähnelt eher einem Junior-Designer, der Ihre Markenrichtlinien studiert hat und keine Angst hat, ein Anliegen zu äußern, bevor Sie schlechte Arbeit in die Produktion schicken.
Diese kollaborative Dynamik — die KI als denkender Partner, nicht als Befehlsausführer — ist wohl der wichtigste Verhaltensunterschied zwischen MCoT-gestütztem Design und prompt-basierter Generierung. Sie verwandelt den Nutzer von einem „Prompt-Ingenieur" in einen Creative Director, der überprüft und lenkt, anstatt mit Syntax zu ringen.
Wer hat MCoT entwickelt: Der Motor hinter Lovart
Diskussionen über KI-Architektur neigen dazu, ins Abstrakte abzudriften. Verankern wir das also in etwas Konkretem: Wer hat das eigentlich gebaut, und welches Geschäft steht dahinter?
Lovart ist das Produkt von LiblibAI, einem in Peking und San Francisco ansässigen KI-Unternehmen, das 2023 von Melvin Chen (CEO) und Wang Haofan (CTO) gegründet wurde. Haofan, ein Absolvent der Carnegie Mellon University, ist in der KI-Forschungsgemeinschaft als Entwickler von InstantID und InstantStyle bekannt — zwei einflussreichen Frameworks zur Bildgenerierung. Das Gründungsteam vereinte tiefgehende Modellexpertise mit der Überzeugung, dass KI-Design-Tools mehr brauchten als bessere Pixel. Sie brauchten besseres Denken.
Diese Überzeugung zog erhebliches Kapital an. Im August 2025 schloss LiblibAI eine Series-B-Finanzierungsrunde über 130 Millionen US-Dollar unter der Führung von Sequoia China und CMC Capital ab — die größte KI-Anwendungsinvestition in China in diesem Jahr. Das Unternehmen nutzte diese Finanzierung, um zwei Dinge gleichzeitig zu skalieren: Modellfähigkeit und Reasoning-Infrastruktur. Das Ergebnis war MCoT, das zusammen mit Lovarts weltweitem Launch im Juli 2025 veröffentlicht wurde.
Lovart betreibt nach eigenen Angaben den weltweit ersten KI-Design-Agenten — keinen zweckgebundenen Bildgenerator, sondern eine End-to-End-Designplattform. Zu den Kernprodukten gehören ChatCanvas (die unendliche Leinwand, auf der Nutzer und KI gemeinsam gestalten), Thinking Mode (angetrieben von MCoT), Touch Edit, Edit Elements und Brand Kit. Es integriert eigene Modelle — Nano Banana Pro für professionelle Bildgenerierung, Seedance 2.0 für Videos mit nativem Audio und 12-Slot-Batch-Verarbeitung — sowie Drittmodelle wie OpenAI's Sora 2, Google's Veo 3 und KuaiShous Kling.
Das Geschäftsmodell ist ein Abonnement für unter 90 US-Dollar pro Monat, das auf das abzielt, was das Unternehmen als "agenturtaugliches Design" zu einem Bruchteil der traditionellen Kosten beschreibt. Die Nutzerbasis umfasst Grafikdesigner, Marketer, E-Commerce-Verkäufer mit Shopify- und Amazon-Shops, Content Creator, die plattformübergreifende Inhalte verwalten, sowie Kleinunternehmer, die sich zuvor keine professionelle Designarbeit leisten konnten.
Was Lovart in einem überfüllten KI-Tools-Markt auszeichnet, ist nicht die Bildqualität — auch Wettbewerber produzieren hervorragende Ergebnisse. Es ist die Reasoning-Schicht. Die meisten KI-Designplattformen sind Generierungstools mit nachträglich hinzugefügten Kollaborationsfunktionen. MCoT ist ein Kollaborationstool mit Generierungsfähigkeiten. Die Architektur spiegelt diesen Unterschied wider.
Warum das über Lovart hinaus bedeutsam ist
Das Ende von „Prompt Engineering" als Karriere
In den Jahren 2024 und 2025 tauchte ein seltsamer neuer Berufstitel auf: Prompt Engineer. Unternehmen stellten Leute ein, deren gesamte Aufgabe darin bestand, die richtige Wortfolge zu formulieren, um KI-Modelle dazu zu bringen, brauchbare Ergebnisse zu produzieren. Es war ein Symptom eines Designfehlers — die Modelle waren leistungsstark, aber unvernünftig. Sie benötigten einen menschlichen Vermittler, um kreative Absicht in maschinenlesbare Anweisungen zu übersetzen.
Reasoning-Engines wie MCoT machen diese Rolle obsolet. Wenn die KI „wir brauchen eine Sommerkampagne" in Zielgruppenanalyse, Asset-Planung und Modell-Orchestrierung zerlegen kann, muss der Mensch keine Prompt-Syntax lernen. Er muss gut darin sein, zu artikulieren, was er will, und zu bewerten, was die KI vorschlägt.
Das ist ein viel natürlicheres Mensch-Computer-Interaktionsmodell. Es ist auch, und das ist entscheidend, ein Modell, das kein technisches Fachwissen zur Bedienung erfordert. Ein Kleinunternehmer ohne Design-Hintergrund kann seine Marke beschreiben und professionelle Ergebnisse erhalten — nicht weil die KI „gut in Kunst" ist, sondern weil die KI im gesamten Designprozess gut ist, von der Strategie bis zur Ausführung.
Die Kluft zwischen traditionellen Design-Workflows und KI-gestützten Ansätzentraditionellen Design-Workflows und KI-gestützten Ansätzenhttps://www.lovart.ai/blog/ai-vs-traditional-design wurde ausführlich diskutiert. Aber was MCoT verändert, ist die Natur dieser Kluft. Es geht nicht mehr um „kann KI mit menschlicher Qualität mithalten?" — die neuesten Modelle können das bereits. Die Frage betrifft jetzt den Prozess: Kann KI am Design Thinking teilnehmen, oder ist sie nur eine sehr schnelle Rendering-Engine? MCoT beantwortet diese Frage mit Architektur, nicht nur mit besseren Modellen.
Was agentisches Design für Teams im Jahr 2026 bedeutet
Die breitere Implikation für Designteams ist eine Untersuchung wert. Wenn eine KI Kampagnenplanung, Modellkoordination, Durchsetzung von Markenkonsistenz und formatübergreifenden Export übernehmen kann — alles aus einer Konversation — was ändert sich dann an der Struktur von Teams?
Das wahrscheinlichste kurzfristige Ergebnis ist nicht Ersatz, sondern Rollentransformation. Senior-Designer verbringen weniger Zeit mit Produktionsausführung und mehr Zeit mit kreativer Leitung und Strategie. Junior-Designer beschleunigen ihre Lernkurve, weil die KI die technische Ausführung übernimmt, während sie Geschmack und Urteilsvermögen entwickeln. Teams, die zuvor separate Spezialisten für Fotografie, Video und Grafikdesign benötigten, können mit kleineren, vielseitigeren Besatzungen arbeiten.
Ein Creative Director einer Digitalagentur beschrieb es so: „Früher verbrachte ich 40 % meiner Zeit mit Regie, 60 % mit Koordination. Mit MCoT sind es 80 % Regie. Die KI übernimmt die Koordination. Das ist eine bessere Nutzung meines Gehirns, und ehrlich gesagt produziert es bessere Arbeit."
Die Werkzeuge sind bereit. Die Workflows sind es nicht — die meisten Teams sind immer noch um werkzeugspezifische Rollen herum organisiert, die Sinn machten, als jedes Ausgabeformat einen anderen Spezialisten und einen anderen Software-Stack erforderte. Die organisatorische Neugestaltung wird hinter der Technologie zurückbleiben, wie es immer der Fall ist. Aber die Richtung ist klar.
FAQ
F: Ist die MCoT-Engine ein separates Produkt oder ist sie in Lovart integriert?
MCoT ist die zentrale Reasoning-Schicht, die Lovarts KI-Design-Agenten antreibt. Es ist kein eigenständiges Produkt, das Sie separat kaufen — es ist die zugrunde liegende Architektur, die Lovarts Design-Agenten von standardmäßigen Bildgeneratoren unterscheidet. Sie greifen über ChatCanvas darauf zu, und sie ist aktiv, wann immer Sie den Thinking Mode verwenden.
F: Wie unterscheidet sich MCoT von einem detaillierten Prompt?
Ein detaillierter Prompt gibt dem Modell spezifischere Anweisungen, aber das Modell verarbeitet sie immer noch als einzelne Generierungsaufgabe. Es plant nicht, koordiniert nicht modellübergreifend und behält keinen Kontext bei. MCoT zerlegt Ihre Anfrage in einen strukturierten Designplan, wählt die richtigen Werkzeuge für jeden Teil aus und stellt Konsistenz über alles sicher, was es produziert. Es ist der Unterschied zwischen einem Koch, dem Sie ein detailliertes Rezept geben, und einem Küchenmanager, dem Sie eine Speisekarte zur Ausführung geben — der eine folgt Anweisungen, der andere orchestriert einen Prozess.
F: Funktioniert MCoT mit allen Modellen von Lovart?
Ja. MCoT koordiniert über Lovarts gesamte Modellbibliothek hinweg — Bildmodelle (Nano Banana Pro, Seedream 4.0, Flux, Recraft V3), Videomodelle (Seedance 2.0, Sora 2, Veo 3, Kling) und unterstützende Werkzeuge. Die Engine wählt das geeignete Modell pro Aufgabe basierend auf den Ausgabeanforderungen aus.
F: Kann ich das „Denken" ausschalten und einfach schnell Bilder generieren?
Ja. Lovart bietet einen Fast Mode für schnelle visuelle Exploration ohne den strategischen Overhead. Der Fast Mode überspringt die MCoT-Reasoning-Kette und generiert direkt — ideal für Brainstorming, Moodboards und schnelle Iterationen. Sie können jederzeit in einem Projekt zwischen Thinking Mode und Fast Mode wechseln.
F: Erinnert sich MCoT an meine Marke über verschiedene Projekte hinweg?
Markenkontext wird innerhalb von Projekten beibehalten. Wenn Sie ein Brand Kit in einem Projekt definiert haben, können Sie es in anderen über das @-Erwähnungssystem referenzieren. Die Engine behandelt Markenregeln als persistenten Zustand, was bedeutet, dass Konsistenz automatisch durchgesetzt wird, anstatt bei jeder Sitzung eine manuelle Neuspezifikation zu erfordern.
F: Was passiert, wenn MCoT eine schlechte strategische Entscheidung trifft?
MCoTs Empfehlungen sind Vorschläge, keine unumkehrbaren Befehle. Sie können jede Entscheidung — Modellauswahl, visuelle Ausrichtung, Asset-Komposition — jederzeit überschreiben. Die Engine lernt aus Ihren Korrekturen: Wenn Sie konsequent bestimmte visuelle Behandlungen zugunsten anderer ablehnen, passt sie ihre zukünftigen Empfehlungen an. Die Designautorität bleibt bei Ihnen; MCoT ist ein denkender Partner, kein Autopilot.
F: Wie lange dauert die „Denkphase" tatsächlich?
Für eine typische Anfrage auf Kampagnenebene (mehrere Assets über Formate hinweg) dauert die Reasoning-Phase 5–15 Sekunden, bevor die Generierung beginnt. Einfache Einzel-Asset-Anfragen werden schneller verarbeitet. Der Kompromiss ist beabsichtigt: Diese zusätzlichen Sekunden produzieren Output, der danach deutlich weniger manuelle Korrektur erfordert. Die meisten Nutzer berichten, dass die End-to-End-Zeit — von der Anfrage bis zum nutzbaren Output — wesentlich kürzer ist als bei Tools, die „sofort starten", aber Iteration erfordern.
Eine Sache, die Sie diese Woche tun können
Wenn Sie prüfen, ob agentische Design-Tools für Ihren Workflow bereit sind, beginnen Sie nicht mit einer Kampagne. Beginnen Sie mit etwas Kleinem, das zählt — ein einzelner Social-Post, ein Produkt-Mockup, ein einfaches Marken-Asset — und führen Sie es durch den Thinking Mode. Achten Sie nicht auf die Output-Qualität (die Sie wahrscheinlich für gut halten), sondern auf das, was Sie nichtnicht tun mussten: kein Prompt-Tweaking, keine Formatkonvertierung, keine manuelle Markendurchsetzung. Der Wert von MCoT wird an der Arbeit gemessen, die Sie nicht mehr tun, nicht an der Arbeit, die Sie anfangen zu tun.
Die KI-Generierungsära gab uns Maschinen, die Bilder machen konnten. Die agentische Ära — das, was MCoT repräsentiert — gibt uns Maschinen, die am Designprozess teilnehmen können. Das ist nicht dasselbe. Und wenn man den Unterschied einmal erlebt hat, fühlt sich die Rückkehr zur One-Shot-Generierung an, als würde man einen Mitarbeiter gegen einen Automaten eintauschen.


